Reinforcement Learning (i.e. Policy Gradient Algorithms)
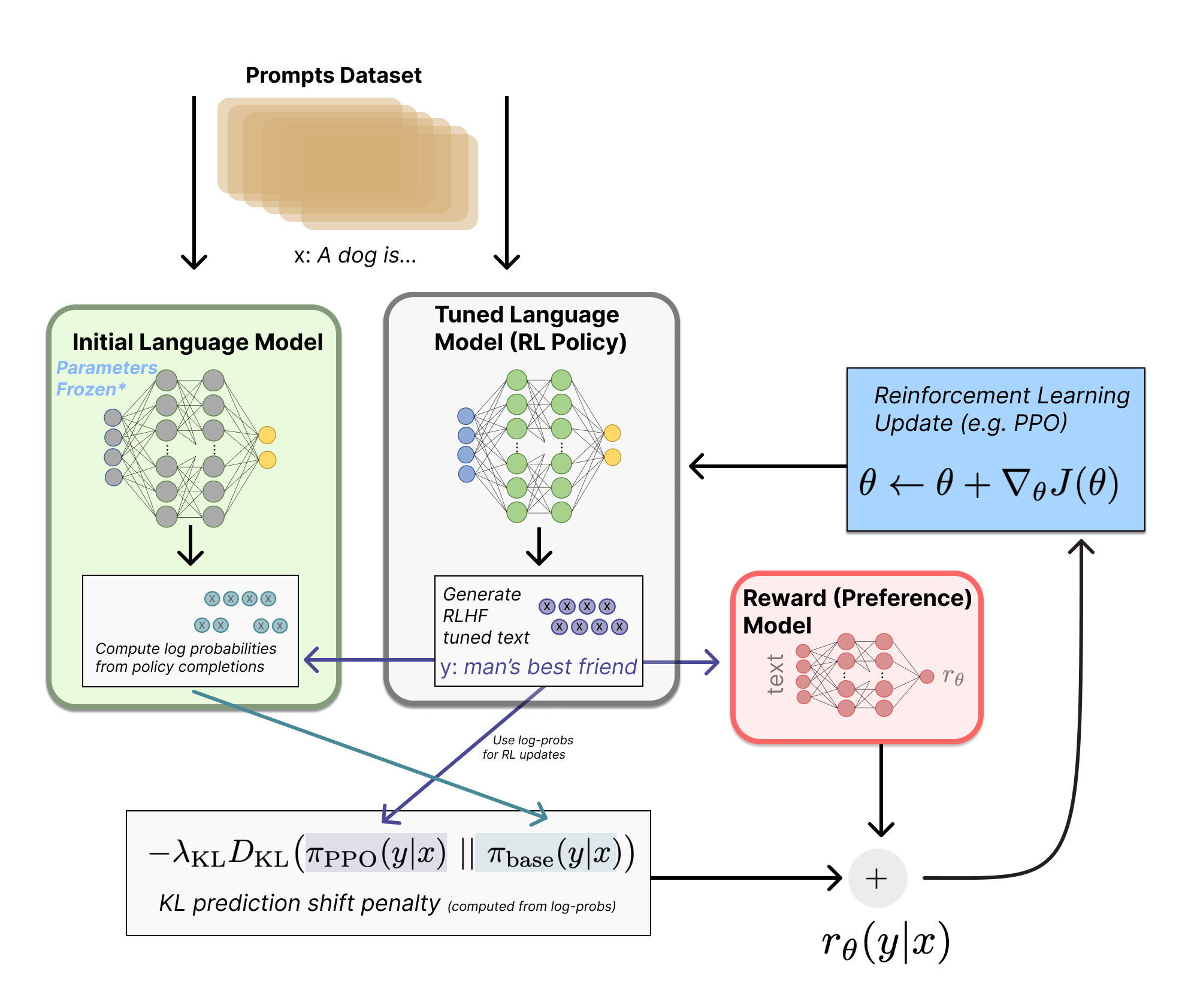
In the RLHF process, the reinforcement learning algorithm slowly updates the model’s weights with respect to feedback from a reward model. The policy – the model being trained – generates completions to prompts in the training set, then the reward model scores them, and then the reinforcement learning optimizer takes gradient steps based on this information (see fig. 1 for an overview). This chapter explains the mathematics and trade-offs across various algorithms used to learn from the signal the reward model gives to on-policy data. These algorithms are run for a period of many epochs, often thousands or millions of batches across a larger set of prompts, with gradient updates in between each of them.
The algorithms that popularized RLHF for language models were policy-gradient reinforcement learning algorithms. These algorithms, such as Proximal Policy Optimization (PPO), Group Relative Policy Optimization (GRPO), and REINFORCE, use recently generated samples to update their model (rather than storing scores in a replay buffer like algorithms, e.g. Deep Q-Networks, DQN, used in popular projects such as AlphaGo). In this section we will cover the fundamentals of the policy gradient algorithms and how they are used in the modern RLHF framework.
At a machine learning level, this section is the subject with the highest complexity in the RLHF process. Though, as with most modern AI models, the largest determining factor on its success is the data provided as inputs to the process.
When RLHF came onto the scene with ChatGPT, it was largely known that they used a variant of PPO, and many initial efforts were built upon that. Over time, multiple research projects showed the promise of REINFORCE-style algorithms [1] [2], touted for its simplicity over PPO without a reward model (saves memory and therefore the number of GPUs required) and with simpler value estimation (no Generalized Advantage Estimation, GAE, which is a method to compute advantages used for variance reduction in policy gradient algorithms). More algorithms have emerged, including Group Relative Policy Optimization, which is particularly popular with reasoning tasks, but in general many of these algorithms can be tuned to fit a specific task. In this chapter, we cover the core policy gradient setup and the three algorithms mentioned above due to their central role in the establishment of a canonical RLHF literature.
For definitions of symbols, see the problem setup chapter.
This chapter uses \((s, a)\) notation from the reinforcement learning literature, where \(s\) denotes states and \(a\) denotes actions. In the language model context, you will often see \((x, y)\) instead, where \(x\) is the prompt and \(y\) is the completion. The \((s, a)\) framing is more general—these algorithms were designed for sequential decision problems where actions are taken at each timestep. However, many RLHF implementations treat the entire completion as a single action, making the \((x, y)\) notation equally valid.
RL Cheatsheet: A one-page reference of all core RL loss functions from this chapter is available at rlhfbook.com/rl-cheatsheet.
Policy Gradient Algorithms
Reinforcement learning algorithms are designed to maximize the future, discounted reward across a trajectory of states, \(s \in \mathcal{S}\), and actions, \(a \in \mathcal{A}\) (for more notation, see Appendix A, Definitions). The objective of the agent, often called the return, is the sum of discounted future rewards (where \(\gamma\in [0,1]\) is a factor that prioritizes near-term rewards) at a given time \(t\):
\[G_t = R_{t+1} + \gamma R_{t+2} + \cdots = \sum_{k=0}^\infty \gamma^k R_{t+k+1}.\qquad{(1)}\]
The return definition can also be estimated as: \[G_{t} = \gamma{G_{t+1}} + R_{t+1}.\qquad{(2)}\]
This return is the basis for learning a value function \(V(s)\) that is the estimated future return given a current state:
\[V(s) = \mathbb{E}\big[G_t | S_t = s \big].\qquad{(3)}\]
All policy gradient algorithms optimize a policy \(\pi_\theta(a\mid s)\) to maximize expected return; this objective can be expressed using the induced value function \(V^{\pi_\theta}(s)\).
Where \(d^{\pi_\theta}(s)\) is the state-visitation distribution induced by policy \(\pi_\theta(a \mid s)\), the objective we maximize can be written as: \[ J(\theta) \;=\; \sum_{s} d^{\pi_\theta}(s) V^{\pi_\theta}(s), \qquad{(4)}\]
In a finite MDP this is a sum over all states, but in practice we never compute it exactly. Instead, we estimate it from data by sampling rollouts from the current policy. In RLHF this typically means sampling prompts \(x_i\) from a dataset and generating completions \(y_i \sim \pi_\theta(\cdot\mid x_i)\), then taking an empirical average such as:
\[ \hat{J}(\theta) = \frac{1}{B}\sum_{i=1}^{B} R(x_i, y_i), \qquad{(5)}\]
or, in an MDP view with per-step rewards,
\[ \hat{J}(\theta) = \frac{1}{B}\sum_{i=1}^{B} \sum_{t=0}^{T_i} \gamma^t r_{i,t}. \qquad{(6)}\]
In practice, RLHF for language models sets \(\gamma = 1\) (no discounting) because the unit of optimization is the collective completion, not individual tokens – this choice is discussed further in the MDP vs. Bandit section later in this chapter.
The core of policy gradient algorithms is computing the gradient with respect to the finite-time expected return over the current policy. With this expected return, \(J\), the parameter update can be computed as follows, where \(\alpha\) is the learning rate:
\[\theta \leftarrow \theta + \alpha \nabla_\theta J(\theta)\qquad{(7)}\]
The core implementation detail is how to compute said gradient.
Another way to pose the RL objective we want to maximize is as follows: \[ J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ R(\tau) \right], \qquad{(8)}\]
where \(\tau = (s_0, a_0, s_1, a_1, \ldots)\) is a trajectory and \(R(\tau) = \sum_{t=0}^\infty r_t\) is the total reward of the trajectory. Alternatively, we can write the expectation as an integral over all possible trajectories: \[ J(\theta) = \int_\tau p_\theta (\tau) R(\tau) d\tau \qquad{(9)}\]
Notice that we can express the trajectory probability as follows, where \(\pi_\theta(a_t|s_t) p(s_{t+1}|s_t, a_t)\) is the transition probability to a group of next states from one state and action: \[ p_\theta (\tau) = p(s_0) \prod_{t=0}^\infty \pi_\theta(a_t|s_t) p(s_{t+1}|s_t, a_t), \qquad{(10)}\]
If we take the gradient of the objective (eq. 8) with respect to the policy parameters \(\theta\): \[ \nabla_\theta J(\theta) = \int_\tau \nabla_\theta p_\theta (\tau) R(\tau) d\tau \qquad{(11)}\]
Notice that we can use the log-derivative trick in order to rewrite the gradient of the integral as an expectation: \[ \begin{aligned} \nabla_\theta \log p_\theta(\tau) &= \frac{\nabla_\theta p_\theta(\tau)}{p_\theta(\tau)} &\text{(from chain rule)} \\ \implies \nabla_\theta p_\theta(\tau) &= p_\theta(\tau) \nabla_\theta \log p_\theta(\tau) &\text{(rearranging)} \end{aligned} \qquad{(12)}\]
Using this log-derivative trick: \[ \begin{aligned} \nabla_\theta J(\theta) &= \int_\tau \nabla_\theta p_\theta (\tau) R(\tau) d\tau \\ &= \int_\tau p_\theta (\tau) \nabla_\theta \log p_\theta (\tau) R(\tau) d\tau \\ &= \mathbb{E}_{\tau \sim \pi_\theta} \left[ \nabla_\theta \log p_\theta (\tau) R(\tau) \right] \end{aligned} \qquad{(13)}\]
Where the final step uses the definition of an expectation under the trajectory distribution \(p_\theta(\tau)\): for any function \(f\), \(\mathbb{E}_{\tau \sim p_\theta}[f(\tau)] = \int_\tau f(\tau)\,p_\theta(\tau)\,d\tau\) (or a sum in the discrete case). Writing it as an expectation is useful because we can approximate it with Monte Carlo rollouts, e.g., \(\frac{1}{B}\sum_{i=1}^{B} f(\tau_i)\) for trajectories \(\tau_i \sim \pi_\theta\).
Back to the derivation, expanding the log probability of the trajectory:
\[ \log p_\theta (\tau) = \log p(s_0) + \sum_{t=0}^\infty \log \pi_\theta(a_t|s_t) + \sum_{t=0}^\infty \log p(s_{t+1}|s_t, a_t) \qquad{(14)}\]
Now, if we take the gradient of the above, we get:
- \(\nabla_\theta \log p(s_0) = 0\) (initial state doesn’t depend on \(\theta\))
- \(\nabla_\theta \log p(s_{t+1}|s_t, a_t) = 0\) (environment transition dynamics don’t depend on \(\theta\))
- only \(\nabla_\theta \log \pi_\theta(a_t|s_t)\) survives
Therefore, the gradient of the log probability of the trajectory simplifies to: \[ \nabla_\theta \log p_\theta (\tau) = \sum_{t=0}^\infty \nabla_\theta \log \pi_\theta(a_t|s_t) \qquad{(15)}\]
Substituting this back in eq. 13, we get: \[ \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^\infty \nabla_\theta \log \pi_\theta(a_t|s_t) R(\tau) \right] \qquad{(16)}\]
Quite often, people use a more general formulation of the policy gradient: \[ g = \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^\infty \nabla_\theta \log \pi_\theta(a_t|s_t) \Psi_t \right] \qquad{(17)}\]
Where \(\Psi_t\) can be the following (where the rewards can also often be discounted by \(\gamma\)), a taxonomy adopted from Schulman et al. 2015 [3]:
- \(R(\tau) = \sum_{t=0}^{\infty} r_t\): total reward of the trajectory.
- \(\sum_{t'=t}^{\infty} r_{t'}\): reward following action \(a_t\), also described as the return, \(G\).
- \(\sum_{t'=t}^{\infty} r_{t'} - b(s_t)\): baselined version of previous formula.
- \(Q^{\pi}(s_t, a_t)\): state-action value function.
- \(A^{\pi}(s_t, a_t)\): advantage function, which yields the lowest possible theoretical variance if it can be computed accurately.
- \(r_t + \gamma V^{\pi}(s_{t+1}) - V^{\pi}(s_t)\): Temporal Difference (TD) residual.
The baseline is a value used to reduce variance of policy updates (more on this below).
For language models, some of these concepts do not make as much sense. For example, for a deterministic policy \(\pi\) the state value is \(V^{\pi}(s_t) = Q^{\pi}(s_t, \pi(s_t))\) (and for the optimal value function one has \(V^*(s_t)=\max_{a_t} Q^*(s_t,a_t)\)). For a stochastic policy, the analogous identity is \(V^{\pi}(s_t) = \mathbb{E}_{a_t \sim \pi(\cdot\mid s_t)}[Q^{\pi}(s_t,a_t)]\). The Bellman equation relates Q to V: in general \(Q^\pi(s_t,a_t) = \mathbb{E}[r_t + \gamma V^\pi(s_{t+1}) \mid s_t, a_t]\), but for language models where state transitions are deterministic, this simplifies to \(Q(s_t,a_t) = r_t + \gamma V(s_{t+1})\). The advantage function measures how much better action \(a_t\) is compared to the average:
\[A(s_t,a_t) = Q(s_t,a_t) - V(s_t) = r_t + \gamma V(s_{t+1}) - V(s_t)\qquad{(18)}\]
This final form is exactly the TD residual (item 6 above). In practice, a learned value function \(\hat{V}\) is used to estimate the advantage via this TD error.
Vanilla Policy Gradient
The vanilla policy gradient implementation optimizes the above expression for \(J(\theta)\) by differentiating with respect to the policy parameters. A simple version, with respect to the overall return, is:
\[\nabla_\theta J(\theta) = \mathbb{E}_\tau \left[ \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t|s_t) R_t \right]\qquad{(19)}\]
A common problem with vanilla policy gradient algorithms is the high variance in gradient updates, which can be mitigated in multiple ways. The high variance comes from the gradient updates being computed from estimating the return \(G\) from an often small set of rollouts in the environment that tend to be susceptible to noise (e.g. the stochastic nature of generating from language models with temperature \(>0\)). The variance across return estimates is higher in domains with sparse rewards, as more of the samples are 0 or 1, rather than closely clustered. In order to alleviate this, various techniques are used to normalize the value estimation, called baselines. Baselines accomplish this in multiple ways, effectively normalizing by the value of the state relative to the downstream action (e.g. in the case of Advantage, which is the difference between the Q value and the value). The simplest baselines are averages over the batch of rewards or a moving average. Even these baselines can de-bias the gradients so \(\mathbb{E}_{a \sim \pi(a|s)}[\nabla_\theta \log \pi_\theta(a|s)] = 0\), improving the learning signal substantially.
Many of the policy gradient algorithms discussed in this chapter build on the advantage formulation of policy gradient:
\[\nabla_\theta J(\theta) = \mathbb{E}_\tau \left[ \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t|s_t) A^{\pi_\theta}(s_t, a_t) \right]\qquad{(20)}\]
REINFORCE
The algorithm REINFORCE is likely a backronym, but the components of the algorithm it represents are quite relevant for modern reinforcement learning algorithms. Defined in the seminal paper Simple statistical gradient-following algorithms for connectionist reinforcement learning [4]:
The name is an acronym for “REward Increment = Nonnegative Factor X Offset Reinforcement X Characteristic Eligibility.”
The three components of this are how to do the reward increment, a.k.a. the policy gradient step. It has three pieces to the update rule:
- Nonnegative factor: This is the learning rate (step size) that must be a positive number, e.g. \(\alpha\) below.
- Offset Reinforcement: This is a baseline \(b\) or other normalizing factor of the reward to improve stability.
- Characteristic Eligibility: This is how the learning becomes attributed per token. It can be a general value, \(e\) per parameter, but is often log probabilities of the policy in modern equations.
Thus, the form looks quite familiar:
\[ \Delta_\theta = \alpha(r - b)e \qquad{(21)}\]
With more modern notation and the generalized return \(G\), the REINFORCE operator appears as:
\[ \nabla_{\theta}\,J(\theta) \;=\; \mathbb{E}_{\tau \sim \pi_{\theta}}\!\Big[ \sum_{t=0}^{T} \nabla_{\theta} \log \pi_{\theta}(a_t \mid s_t)\,(G_t - b(s_t)) \Big], \qquad{(22)}\]
Here, the value \(G_t - b(s_t)\) is the advantage of the policy at the current state, so we can reformulate the policy gradient in a form that we continue later with the advantage, \(A\):
\[ \nabla_{\theta}\,J(\theta) \;=\; \mathbb{E}_{\tau \sim \pi_{\theta}}\!\Big[ \sum_{t=0}^{T} \nabla_{\theta} \log \pi_{\theta}(a_t \mid s_t)\,A_t \Big], \qquad{(23)}\]
REINFORCE is a specific implementation of vanilla policy gradient that uses a Monte Carlo estimator of the gradient.
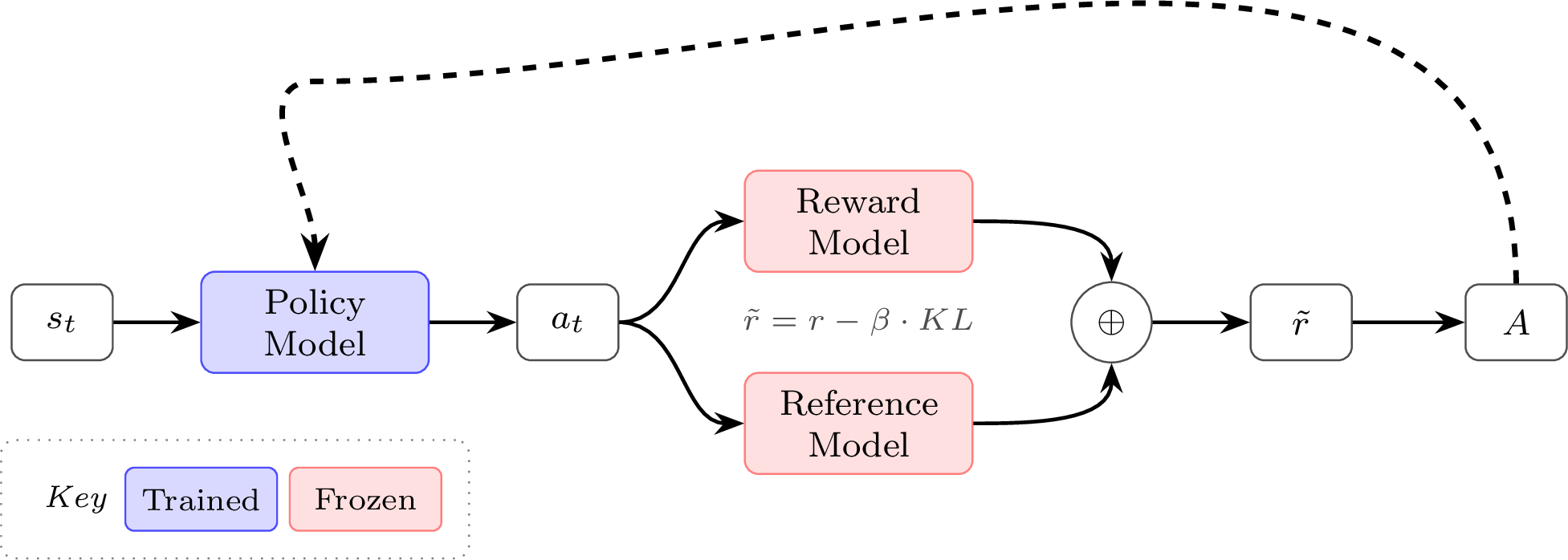
REINFORCE Leave One Out (RLOO)
The core implementation detail of REINFORCE Leave One Out versus standard REINFORCE is that it takes the average reward of the other samples in the batch to compute the baseline – rather than averaging over all rewards in the batch [5], [1], [6].
Crucially, this only works when generating multiple trajectories (completions) per state (prompt), which is common practice in multiple domains of fine-tuning language models with RL.
Specifically, for the REINFORCE Leave-One-Out (RLOO) baseline, given \(K\) sampled trajectories (actions taken conditioned on a prompt) \(a_1, \dots, a_K\), to a given prompt \(s\) we define the baseline explicitly as the following per-prompt:
\[ b(s, a_k) = \frac{1}{K-1}\sum_{i=1, i\neq k}^{K} R(s, a_i), \qquad{(24)}\]
resulting in the advantage:
\[ A(s, a_k) = R(s, a_k) - b(s, a_k). \qquad{(25)}\]
Equivalently, this can be expressed as:
\[ A(s, a_k) = \frac{K}{K - 1}\left(R(s, a_k) - \frac{1}{K}\sum_{i=1}^{K} R(s, a_i)\right). \qquad{(26)}\]
This is a simple, low-variance per-prompt advantage estimate that is closely related to the group-relative advantage used in Group Relative Policy Optimization, GRPO (discussed shortly, after Proximal Policy Optimization, PPO). In practice, GRPO-style training mainly differs in how it applies the KL regularizer (as an explicit loss term vs. folded into the reward) and whether it uses PPO-style ratio clipping. To be specific, the canonical GRPO implementation applies the KL penalty at the loss level, where the derivation for RLOO or traditional policy-gradients apply the KL penalty to the reward itself. With the transition from RLHF to reasoning and reinforcement learning with verifiable rewards (RLVR), the prevalence of KL penalties has decreased overall, with many reasoning adaptations of RLHF code turning them off entirely. Still, the advantage from RLOO could be combined with the clipping of PPO, showing how similar many of these algorithms are.
RLOO and other algorithms that do not use a value network – an additional model copy (a critic) that predicts a scalar value \(V(s_t)\) per token – assign the same sequence-level advantage (or reward) to every token when computing the loss. Algorithms that use a learned value network, such as PPO, assign a different value to every token individually, discounting from the final reward achieved at the EOS token. With a KL distance penalty, RLOO aggregates the per-token KL over the completion and folds that scalar into the sequence reward, so the resulting advantage is broadcast to all tokens. PPO subtracts a per-token KL from the per-token reward before computing \(A_t\), giving token-level credit assignment. GRPO typically retains a sequence-level advantage but adds a separate per-token term to the loss, rather than subtracting it from the reward. These details and trade-offs are discussed later in the chapter.
Proximal Policy Optimization (PPO)
Proximal Policy Optimization (PPO) [7] is one of the foundational algorithms behind Deep RL’s successes (such as OpenAI’s Five, which mastered DOTA 2 [8] and large amounts of research). The objective that PPO maximizes, with respect to the advantages and the policy probabilities, is as follows:
\[J(\theta) = \min\left(\frac{\pi_\theta(a|s)}{\pi_{\theta_{\text{old}}}(a|s)}A, \text{clip} \left( \frac{\pi_\theta(a|s)}{\pi_{\theta_{\text{old}}}(a|s)}, 1-\varepsilon, 1+\varepsilon \right) A \right).\qquad{(27)}\]
Here, \(\pi_\theta(a|s)\) is the current policy being optimized and \(\pi_{\theta_{\text{old}}}(a|s)\) is the policy that was used to collect the training data (i.e., the policy from the previous iteration). The ratio between these two policies emerges from importance sampling, which allows us to reuse data collected under an old policy to estimate gradients for a new policy.
Recall from the advantage formulation of the policy gradient (eq. 20) that we have: \[\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t|s_t) A^{\pi_\theta}(s_t, a_t) \right].\qquad{(28)}\]
This expectation is taken over trajectories sampled from \(\pi_\theta\), but in practice we want to take multiple gradient steps on a batch of data that was collected from a fixed policy \(\pi_{\theta_{\text{old}}}\). To correct for this distribution mismatch, we multiply by the importance weight \(\frac{\pi_\theta(a|s)}{\pi_{\theta_{\text{old}}}(a|s)}\), which reweights samples to account for how much more or less likely they are under the current policy versus the data-collection policy. Without constraints, optimizing this importance-weighted objective can lead to destructively large policy updates when the ratio diverges far from 1. PPO addresses this by clipping the ratio to the range \([1-\varepsilon, 1+\varepsilon]\), ensuring that the policy cannot change too drastically in a single update.
For completeness, PPO is typically written as an expected clipped surrogate objective over timesteps:
\[ J(\theta) = \mathbb{E}_{t}\left[ \min\left(R_t(\theta)A_t,\ \text{clip}(R_t(\theta),1-\varepsilon,1+\varepsilon)A_t\right) \right], \qquad R_t(\theta)=\frac{\pi_\theta(a_t\mid s_t)}{\pi_{\theta_{\text{old}}}(a_t\mid s_t)}. \qquad{(29)}\]
The objective is often converted into a loss function by simply adding a negative sign, which makes the optimizer seek to make it as negative as possible.
For language models, the objective (or loss) is computed per token, which intuitively can be grounded in how one would compute the probability of the entire sequence of autoregressive predictions – by a product of probabilities. From there, the common implementation is with log-probabilities that make the computation simpler to perform in modern language modeling frameworks.
\[ J(\theta) = \frac{1}{|a|} \sum_{t=0}^{|a|} \min\left(\frac{\pi_\theta(a_{t}|s_t)}{\pi_{\theta_{\text{old}}}(a_{t}|s_t)}A_{t}, \text{clip} \left( \frac{\pi_\theta(a_{t}|s_t)}{\pi_{\theta_{\text{old}}}(a_{t}|s_t)}, 1-\varepsilon, 1+\varepsilon \right) A_{t} \right). \qquad{(30)}\]
This is the per-token version of PPO, which also applies to other policy-gradient methods, but is explored further later in the implementation section of this chapter. Here, the term for averaging by the number of tokens in the action, \(\frac{1}{|a|}\), comes from common implementation practices, but is not in a formal derivation of the loss (shown in [9]).
Here we will explain the different cases this loss function triggers given various advantages and policy ratios. At an implementation level, the inner computations for PPO involve two main terms: 1) a standard policy gradient with a learned advantage and 2) a clipped policy gradient based on a maximum step size.
To understand how different situations emerge, we can define the policy ratio as:
\[R(\theta) = \frac{\pi_\theta(a|s)}{\pi_{\theta_{\text{old}}}(a|s)}\qquad{(31)}\]
The policy ratio is a centerpiece of PPO and related algorithms. It emerges from computing the gradient of a policy and controls the parameter updates in a very intuitive way. For any batch of data, the policy ratio starts at 1 for the first gradient step for that batch, since \(\pi_{\theta}\) is the same as \(\pi_{\theta_{\text{old}}}\) at this point. Then, in the next gradient step, the policy ratio will be above one if that gradient step increased the likelihood of certain tokens with an associated positive advantage, or less than one for the other case. A common practice is to take 1-4 gradient steps per batch with policy gradient algorithms before updating \(\pi_{\theta_{\text{old}}}\).
Understanding the PPO Objective
Overall, the PPO objective can be visualized by two lines of a plot of objective versus policy ratio, which is shown in fig. 5. The PPO objective is maximized by changing the probability of the sampled actions. Numerically, the objective controls for both positive and negative advantage cases by clever use of the minimum operation, making it so the update is at most pushed by an epsilon distance away from a policy ratio of 1.
Within the trust region, PPO operates the same as other policy gradient algorithms. This is by design! The trust region is a concept used to cap the maximum step size of PPO and its peer algorithms for stability of updates. The core of the PPO algorithm, the clip and min/max functions, is to define this region. The objective becomes flat outside of it.
The idea of a “trust region” comes from the numerical optimization literature [10], but was popularized within Deep RL from the algorithm Trust Region Policy Optimization (TRPO), which is accepted as the predecessor to PPO [11]. The trust region is the area where the full policy-gradient steps are applied, as the updates are not “clipped” by the max/min operations of the PPO objective.
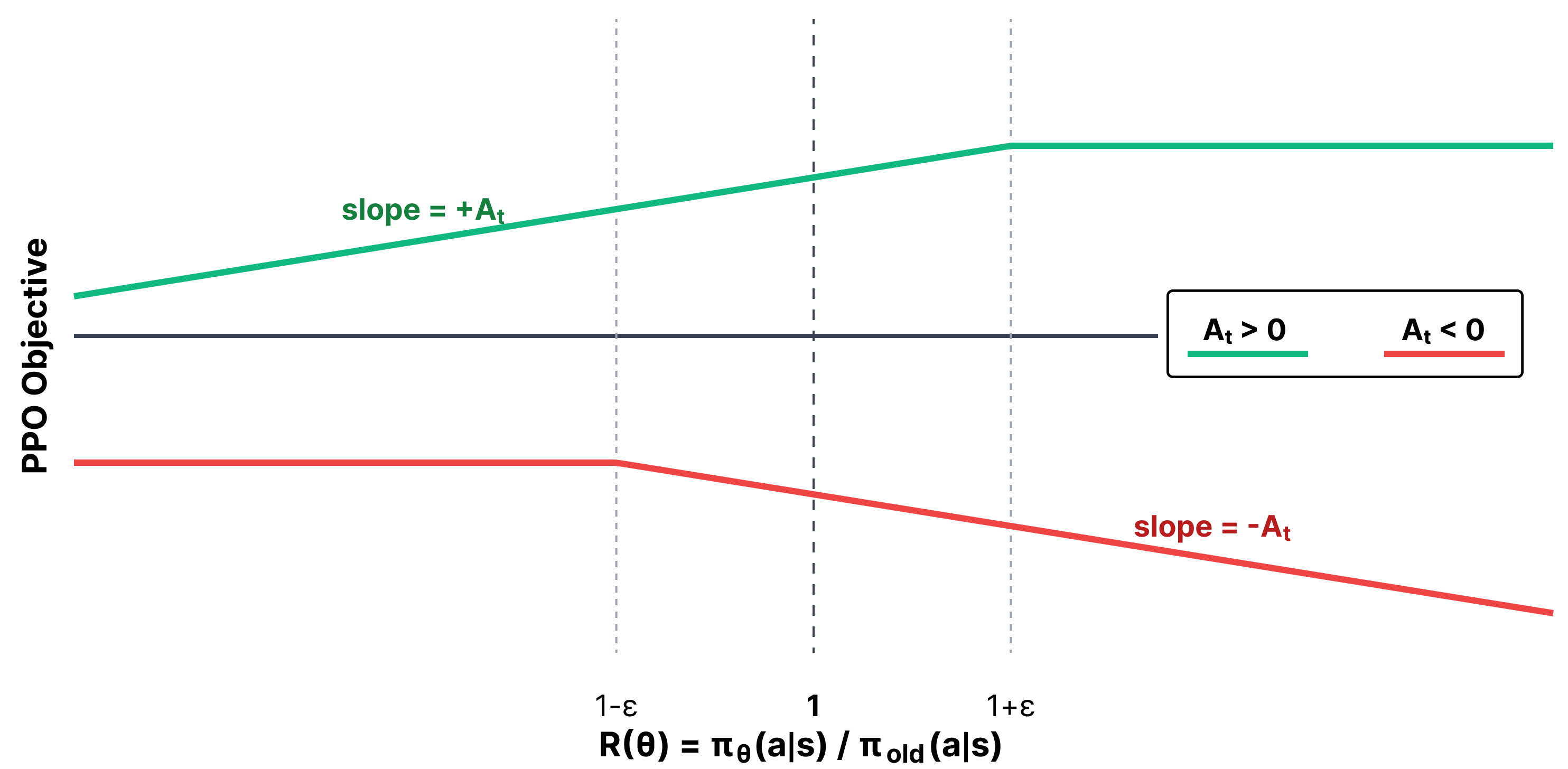
The policy ratio and advantage together can occur in a few different configurations. We will split the cases into two groups: positive and negative advantage.
Positive Advantage (\(A_t > 0\))
This means that the action taken was beneficial according to the value function, and we want to increase the likelihood of taking that action in the future. Now, let’s look at different cases for the policy ratio \(R(\theta)\):
\(R(\theta) < 1 - \varepsilon\):
- Interpretation: Action is less likely with the new policy than the old policy
- Unclipped Term: \(R(\theta) A_t\)
- Clipped Term: \((1 - \varepsilon) A_t\)
- Objective: \(R(\theta) A_t\)
- Gradient: \(\nabla_\theta R(\theta) A_t \neq 0\)
- What happens: Normal policy-gradient update - increase likelihood of action
\(1 - \varepsilon \leq R(\theta) \leq 1 + \varepsilon\):
- Interpretation: Action is almost equally likely with the new policy as the old policy
- Unclipped Term: \(R(\theta) A_t\)
- Clipped Term: \(R(\theta) A_t\)
- Objective: \(R(\theta) A_t\)
- Gradient: \(\nabla_\theta R(\theta) A_t \neq 0\)
- What happens: Normal policy-gradient update - increase likelihood of action
\(1 + \varepsilon < R(\theta)\):
- Interpretation: Action is more likely with the new policy than the old policy
- Unclipped Term: \(R(\theta) A_t\)
- Clipped Term: \((1 + \varepsilon) A_t\)
- Objective: \((1 + \varepsilon) A_t\)
- Gradient: \(\nabla_\theta (1 + \varepsilon) A_t = 0\)
- What happens: NO UPDATE - action is already more likely under the new policy
To summarize, when the advantage is positive (\(A_t>0\)), we want to boost the probability of the action. Therefore:
- We perform gradient steps only in the case when \(\pi_{\text{new}}(a) \leq (1+\varepsilon) \pi_{\text{old}}(a)\). Intuitively, we want to boost the probability of the action, since the advantage was positive, but not boost it so much that we have made it substantially more likely.
- Crucially, when \(\pi_{\text{new}}(a) > (1+\varepsilon) \pi_{\text{old}}(a)\), then we don’t perform any update, and the gradient of the clipped objective is \(0\). Intuitively, the action is already more expressed with the new policy, so we don’t want to over-reinforce it.
Negative Advantage (\(A_t < 0\))
This means that the action taken was detrimental according to the value function, and we want to decrease the likelihood of taking that action in the future. Now, let’s look at different cases for the policy ratio \(R(\theta)\):
\(R(\theta) < 1 - \varepsilon\):
- Interpretation: Action is less likely with the new policy than the old policy
- Unclipped Term: \(R(\theta) A_t\)
- Clipped Term: \((1 - \varepsilon) A_t\)
- Objective: \((1 - \varepsilon) A_t\)
- Gradient: \(\nabla_\theta (1 - \varepsilon) A_t = 0\)
- What happens: NO UPDATE - action is already less likely under the new policy
\(1 - \varepsilon \leq R(\theta) \leq 1 + \varepsilon\):
- Interpretation: Action is almost equally likely with the new policy as the old policy
- Unclipped Term: \(R(\theta) A_t\)
- Clipped Term: \(R(\theta) A_t\)
- Objective: \(R(\theta) A_t\)
- Gradient: \(\nabla_\theta R(\theta) A_t \neq 0\)
- What happens: Normal policy-gradient update - decrease likelihood of action
\(1 + \varepsilon < R(\theta)\):
- Interpretation: Action is more likely with the new policy than the old policy
- Unclipped Term: \(R(\theta) A_t\)
- Clipped Term: \((1 + \varepsilon) A_t\)
- Objective: \(R(\theta) A_t\)
- Gradient: \(\nabla_\theta R(\theta) A_t \neq 0\)
- What happens: Normal policy-gradient update - decrease likelihood of action
To summarize, when the advantage is negative (\(A_t < 0\)), we want to decrease the probability of the action. Therefore:
- We perform gradient steps only in the case when \(\pi_{\text{new}}(a) \geq (1-\varepsilon) \pi_{\text{old}}(a)\). Intuitively, we want to decrease the probability of the action, since the advantage was negative, and we do so proportional to the advantage.
- Crucially, when \(\pi_{\text{new}}(a) < (1-\varepsilon) \pi_{\text{old}}(a)\), then we don’t perform any update, and the gradient of the clipped objective is \(0\). Intuitively, the action is already less likely under the new policy, so we don’t want to over-suppress it.
It is crucial to remember that PPO within the trust region is roughly the same as standard forms of policy gradient.
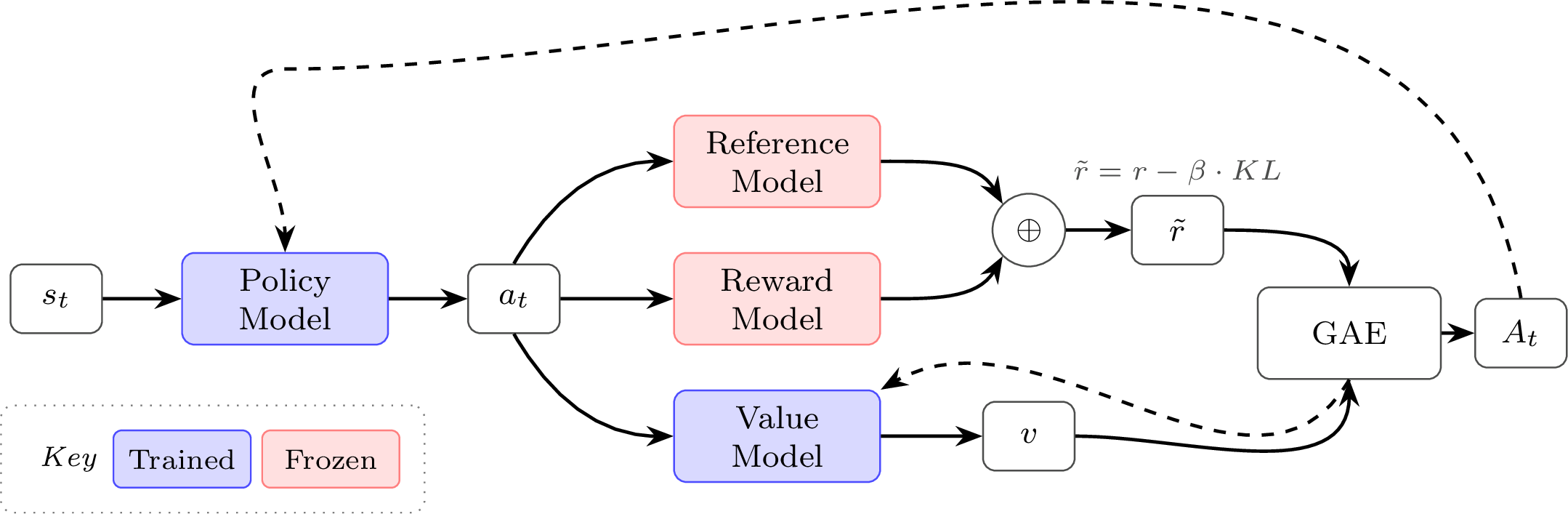
Value Functions and PPO
The value function within PPO is an additional copy of the model that is used to predict the value per token. The value of a token (or state) in traditional RL is predicting the future return from that moment, often with discounting. This value in PPO is used as a learned baseline, representing an evolution of the simple Monte Carlo version used with REINFORCE (which doesn’t need the learned value network). This highlights how PPO is an evolution of REINFORCE and vanilla policy-gradient in multiple forms, across the optimization form, baseline, etc. In practice, with PPO and other algorithms used for language models, this is predicting the return of each token after the deduction of KL penalties (the per-token loss includes the KL from the reward traditionally, as discussed).
There are a few different methods (or targets) used to learn the value functions. Generalized Advantage Estimation (GAE) is considered the state-of-the-art and canonical implementation in modern systems, but it carries more complexity by computing the value prediction error over multiple steps – see the later section on GAE in this chapter. A value function can also be learned with Monte Carlo estimates from the rollouts used to update the policy. PPO has two losses – one to learn the value function and another to use that value function to update the policy.

A simple example implementation of a value network loss is shown below.
# Basic PPO critic targets & loss (no GAE)
#
# B: Batch Size
# L: Completion Length
# Inputs:
# rewards: (B, L) post-KL per-token rewards; EOS row includes outcome
# done_mask: (B, L) 1.0 at terminal token (EOS or truncation if penalized), else 0.0
# completion_mask: (B, L) 1.0 on response tokens to supervise (ignore the prompt)
# values: (B, L) current critic predictions V_theta(s_t)
# because a value network is a running update
# old_values: (B, L) critic predictions at rollout time V_{theta_old}(s_t)
# gamma: discount factor, float (often 1.0 for LM RLHF)
# epsilon_v: float value clip range (e.g., 0.2), similar to PPO Loss Update itself, optional
#
# Returns:
# value_loss: scalar; advantages: (B, L) detached (for policy loss)
B, L = rewards.shape
# 1) Monte Carlo returns per token (reset at terminals)
# Apply discounting, if enabled
returns = torch.zeros_like(rewards)
running = torch.zeros(B, device=rewards.device, dtype=rewards.dtype)
for t in reversed(range(L)):
running = rewards[:, t] + gamma * (1.0 - done_mask[:, t]) * running
returns[:, t] = running
targets = returns # y_t = G_t (post-KL)
# 2) PPO-style value clipping (optional)
v_pred = values
v_old = old_values
v_clip = torch.clamp(v_pred, v_old - epsilon_v, v_old + epsilon_v)
vf_unclipped = 0.5 * (v_pred - targets) ** 2
vf_clipped = 0.5 * (v_clip - targets) ** 2
vf_loss_tok = torch.max(vf_unclipped, vf_clipped)
# 3) Mask to response tokens and aggregate
denom = completion_mask.sum(dim=1).clamp_min(1)
value_loss = ((vf_loss_tok * completion_mask).sum(dim=1) / denom).mean()
# 4) Advantages for policy loss (no GAE): A_t = G_t - V(s_t)
advantages = (targets - v_pred).detach()
# The value loss is applied later, often with the PG loss, e.g.
# total_loss = policy_loss + vf_coef * value_lossGroup Relative Policy Optimization (GRPO)
Group Relative Policy Optimization (GRPO) is introduced in DeepSeekMath [12], and used in other DeepSeek works, e.g. DeepSeek-V3 [13] and DeepSeek-R1 [14]. GRPO can be viewed as a PPO-inspired algorithm with a very similar surrogate loss, but it avoids learning a value function with another copy of the original policy language model (or another checkpoint for initialization). This brings two posited benefits:
- Avoiding the challenge of learning a value function from a LM backbone, where research hasn’t established best practices.
- Saves memory by not needing to keep the extra set of model weights in memory (going from needing the current policy, the reference policy, and a value function, to just the first two copies).
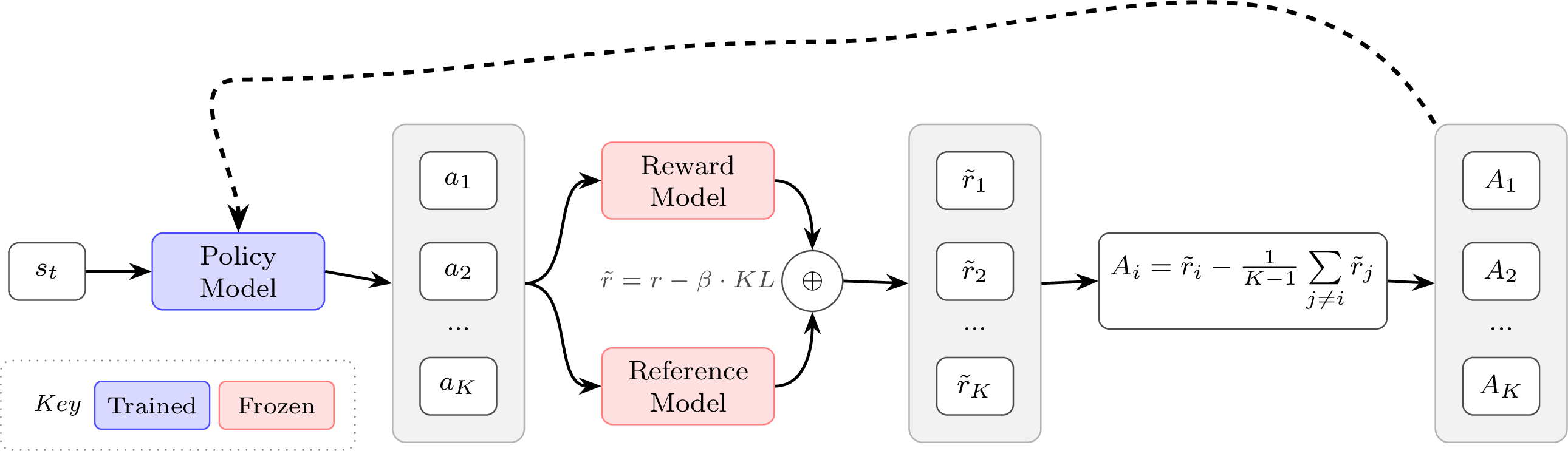
GRPO does this by simplifying the value estimation and assigning the same value to every token in the episode (i.e. in the completion to a prompt, each token gets assigned the same value rather than discounted rewards in a standard value function) by estimating the advantage or baseline. The estimate is done by collecting multiple completions (\(a_i\)) and rewards (\(r_i\)), i.e. a Monte Carlo estimate, from the same initial state / prompt (\(s\)).
To state this formally, the GRPO objective is very similar to the PPO objective above. For GRPO, the objective (or loss) is accumulated over a group of completions \(\{a_1, a_2, ..., a_G\}\) to a given prompt \(s\). Here, we show the GRPO objective:
\[J(\theta) = \frac{1}{G}\sum_{i=1}^G \left(\min\left(\frac{\pi_\theta(a_i|s)}{\pi_{\theta_{\text{old}}}(a_i|s)}A_i, \text{clip} \left( \frac{\pi_\theta(a_i|s)}{\pi_{\theta_{\text{old}}}(a_i|s)}, 1-\varepsilon, 1+\varepsilon \right) A_i \right) - \beta \mathcal{D}_{\text{KL}}(\pi_\theta||\pi_{\text{ref}})\right).\qquad{(32)}\]
Note that relative to PPO, the standard implementation of GRPO includes the KL distance in the loss. As above, we can expand this into a per-token computation:
\[\begin{aligned} J(\theta) = \frac{1}{G}\sum_{i=1}^G \frac{1}{|a_i|} \sum_{t=1}^{|a_i|} \Bigg( &\min\!\left(\frac{\pi_\theta(a_{i,t}|s_{i})}{\pi_{\theta_{\text{old}}}(a_{i,t}|s_{i})}A_{i,t},\; \text{clip} \left( \frac{\pi_\theta(a_{i,t}|s_{i})}{\pi_{\theta_{\text{old}}}(a_{i,t}|s_{i})}, 1-\varepsilon, 1+\varepsilon \right) A_{i,t} \right) \\ &- \beta \mathcal{D}_{\text{KL}}\!\left(\pi_\theta(\cdot|s_{i})\|\pi_{\text{ref}}(\cdot|s_{i})\right) \Bigg) \end{aligned}\qquad{(33)}\]
With the advantage computation for the completion index \(i\):
\[A_i = \frac{r_i - \text{mean}({r_1, r_2, \cdots, r_G})}{\text{std}({r_1, r_2, \cdots, r_G})}.\qquad{(34)}\]
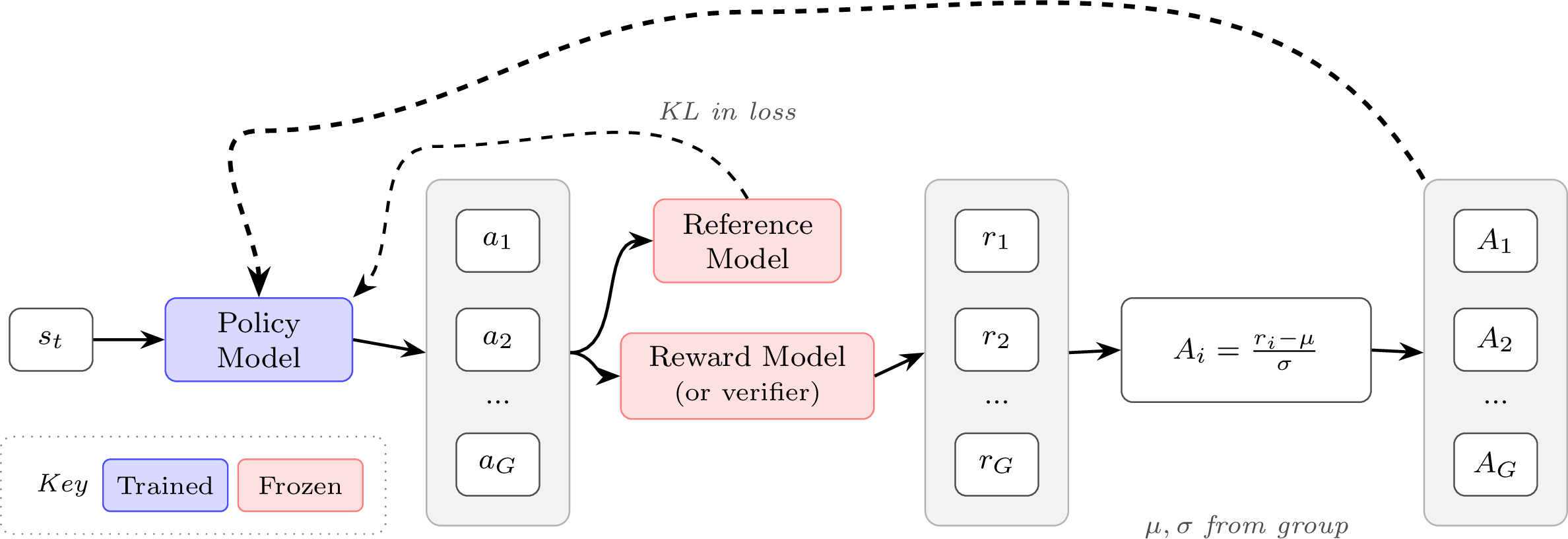
Intuitively, the GRPO update is comparing multiple answers to a single question within a batch. The model learns to become more like the answers marked as correct and less like the others. This is a very simple way to compute the advantage, which is the measure of how much better a specific action is than the average at a given state. Relative to PPO, REINFORCE, and broadly RLHF performed with a reward model rating (relative to output reward), GRPO is often run with a far higher number of samples per prompt because the advantage is entirely about the relative value of a completion to its peers from that prompt. Here, the current policy generates multiple responses to a given prompt, and the group-wise GRPO advantage estimate is given valuable context. PPO and vanilla policy-gradient algorithms were designed to accurately estimate the reward of every completion (in fact, more completions can do little to improve the value estimate in some cases). GRPO and its variants are particularly well-suited to modern language model tools, where multiple completions to a given prompt is very natural (especially when compared to, e.g., multiple actions from a set environment state in a robotic task).
The advantage computation for GRPO has trade-offs in its biases. The normalization by standard deviation is rewarding questions in a batch that have a low variation in answer correctness. For questions with either nearly all correct or all incorrect answers, the standard deviation will be lower and the advantage will be higher. [9] proposes removing the standard deviation term given this bias, but this comes at the cost of down-weighing questions that were all incorrect with a few correct answers, which could be seen as valuable learning signal for the model. Those high-variance prompts can be exactly the hardest cases, where only a few sampled completions find the correct answer and provide a strong training signal.
eq. 34 is the implementation of GRPO when working with outcome supervision (either a standard reward model or a single verifiable reward) and a different implementation is needed with process supervision. In this case, GRPO computes the advantage as the sum of the normalized rewards for the following reasoning steps.
Finally, GRPO’s advantage estimation can also be applied without the PPO clipping to more vanilla versions of policy gradient (e.g. REINFORCE), but it is not the canonical form. As an example of how these algorithms are intertwined, we can show that the advantage estimation in a variant of GRPO, Dr. GRPO (GRPO Done Right) [9], is equivalent to the RLOO estimation (which uses the average reward of other samples as its baseline) up to a constant scaling factor (which normally does not matter due to implementation details to normalize the advantage). Dr. GRPO removes the standard deviation normalization term from eq. 34 – note that this also scales the advantage up, which is equivalent to increasing the GRPO learning rate on samples with a variance in answer scores. This addresses a bias towards questions with low reward variance – i.e. almost all the answers are right or wrong – but comes at a potential cost where problems where just one sample gets the answer right are important to learn from. The Dr. GRPO advantage for completion \(i\) within a group of size \(G\) is defined as:
\[ \tilde{A}_i = r_i - \text{mean}({r_1, r_2, \cdots, r_G}) = r_i - \frac{1}{G}\sum_{j=1}^G r_j \qquad{(35)}\]
Here, in the same notation, we can recall the RLOO advantage estimation as:
\[ A_i^\text{RLOO} = r_i - \frac{1}{G-1}\sum_{j=1, i\neq j}^G r_j \qquad{(36)}\]
Thus, if we multiply the Dr. GRPO advantage definition by \(\frac{G}{G-1}\) we can see a scaled equivalence:
\[ \begin{aligned} \frac{G}{G-1} \tilde{A}_i &= \frac{G}{G-1} \left( r_i - \frac{1}{G}\sum_{j=1}^G r_j \right) \\ &= \frac{G}{G-1} r_i - \frac{1}{G-1} \sum_{j=1}^G r_j \\ &= \frac{G}{G-1} r_i - \frac{1}{G-1} \sum_{j=1, j\neq i}^G r_j - \frac{1}{G-1} r_i \\ &= r_i \left( \frac{G}{G-1} - \frac{1}{G-1} \right) - \frac{1}{G-1} \sum_{j=1, j\neq i}^G r_j \\ &= r_i - \frac{1}{G-1} \sum_{j=1, j\neq i}^G r_j \\ &= A_i^{\text{RLOO}} \end{aligned} \qquad{(37)}\]
Group Sequence Policy Optimization (GSPO)
When taking multiple gradient steps on a batch of data collected from a previous policy, importance sampling is required to correct for the distribution mismatch between the data-collection policy and the current policy being optimized. The standard importance sampling identity allows us to estimate expectations under one distribution using samples from another:
\[ \mathbb{E}_{p}[f(x)] = \mathbb{E}_{q}\left[f(x) \frac{p(x)}{q(x)}\right], \qquad{(38)}\]
where \(p\) is the target distribution, \(q\) is the sampling distribution, and \(\frac{p(x)}{q(x)}\) is the importance weight. In policy gradient methods, \(p = \pi_\theta\) is the current policy we want to optimize and \(q = \pi_{\theta_{\text{old}}}\) is the policy that generated the training data. This allows us to reweight samples collected under \(\pi_{\theta_{\text{old}}}\) to estimate gradients for \(\pi_\theta\), enabling multiple gradient steps per batch of rollouts.
This distribution mismatch arises in two common scenarios: (1) taking multiple gradient steps on a single batch, where \(\pi_\theta\) drifts from \(\pi_{\theta_{\text{old}}}\) after each update, and (2) in asynchronous training systems where the inference backend (e.g., vLLM) and training backend (e.g., FSDP) may have different model weights due to synchronization delays (see the Asynchronicity section later in this chapter, which emerged particularly with the focus on RL for verifiable rewards, but is also used in RLHF setups).
PPO and GRPO apply importance sampling at the token level and stabilize learning by clipping the surrogate objective. However, this approach has a subtle failure mode: when a token’s importance ratio moves outside the clipping range \([1-\varepsilon, 1+\varepsilon]\), that token receives zero gradient. For rare but important tokens—such as key reasoning steps that the model initially assigns low probability—this “token dropping” can prevent the model from learning to produce them more reliably.
Group Sequence Policy Optimization (GSPO) [15] extends GRPO by computing importance ratios at the sequence level rather than the token level. The practical motivation for this algorithm, and its peer modifying how importance sampling is computed for policy gradient algorithms, CISPO, that we will discuss later, is that the per-token importance sampling ratio is often numerically unstable. The conceptual motivation is that when rewards are assigned at the sequence level (as in most RLHF and RLVR setups), the importance sampling correction should match that granularity.
Token-level ratios can behave erratically for long sequences and/or large, sparse models (e.g. modern mixture of experts, MoE, models): a single token with a large ratio can dominate the policy update, or many tokens may get clipped independently within a response, fragmenting the learning signal across a single response. GSPO addresses this by computing a single importance weight per response.
Recall that the probability of a full response factorizes autoregressively:
\[ \pi_\theta(a \mid s) = \prod_{t=1}^{|a|} \pi_\theta(a_t \mid s, a_{<t}). \qquad{(39)}\]
Note that for simplicity, we often shorten the conditional policy, \(\pi_\theta(a_t \mid s, a_{<t})\), as \(\pi_\theta(a_t \mid s)\), which implicitly contains the previous actions (tokens) in a completion. GSPO defines a length-normalized sequence-level importance ratio using the geometric mean (to avoid numerical issues with long sequences):
\[ \rho_i(\theta) = \left( \frac{\pi_\theta(a_i \mid s)}{\pi_{\theta_{\text{old}}}(a_i \mid s)} \right)^{\frac{1}{|a_i|}} = \exp\left( \frac{1}{|a_i|} \sum_{t=1}^{|a_i|} \log \frac{\pi_\theta(a_{i,t} \mid s, a_{i,<t})}{\pi_{\theta_{\text{old}}}(a_{i,t} \mid s, a_{i,<t})} \right). \qquad{(40)}\]
The GSPO objective mirrors GRPO but uses this sequence-level ratio:
\[ J_{\text{GSPO}}(\theta) = \mathbb{E}_{s \sim \mathcal{D},\, \{a_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}(\cdot \mid s)} \left[ \frac{1}{G} \sum_{i=1}^G \min\left( \rho_i(\theta) A_i,\, \text{clip}(\rho_i(\theta), 1-\varepsilon, 1+\varepsilon) A_i \right) \right]. \qquad{(41)}\]
Because the ratio is length-normalized, the clipping range \(\varepsilon\) operates on a per-token average scale, making the effective constraint comparable across responses of different lengths. In implementation, the sequence-level weight \(\rho_i\) is applied uniformly to all tokens in response \(a_i\), which simplifies gradient computation while maintaining the sequence-level IS correction.
The advantage computation remains the same as GRPO (eq. 34), using the group-relative mean and standard deviation normalization, which can be modified as done in other derivative studies of GRPO. GSPO can be summarized as “GRPO with sequence-level importance ratios”—the IS correction granularity is matched to the reward granularity.
Clipped Importance Sampling Policy Optimization (CISPO)
Clipped Importance Sampling Policy Optimization (CISPO) [16] takes a different approach: rather than clipping the surrogate objective, CISPO clips the importance weights themselves while preserving gradients for all tokens. The objective uses a stop-gradient on the clipped importance weight, returning to a REINFORCE-style formulation instead of the PPO-style, two-sided clipping:
\[ J_{\text{CISPO}}(\theta) = \mathbb{E}_{s \sim \mathcal{D},\, \{a_i\}_{i=1}^K \sim \pi_{\theta_{\text{old}}}(\cdot \mid s)} \left[ \frac{1}{\sum_{i=1}^K |a_i|} \sum_{i=1}^K \sum_{t=1}^{|a_i|} \text{sg}\left( \hat{\rho}_{i,t}(\theta) \right) A_{i,t} \log \pi_\theta(a_{i,t} \mid s, a_{i,<t}) \right], \qquad{(42)}\]
where \(\text{sg}(\cdot)\) denotes stop-gradient (the weight is used but not differentiated through), and the clipped importance ratio is:
\[ \hat{\rho}_{i,t}(\theta) = \text{clip}\left( \rho_{i,t}(\theta),\, 1 - \varepsilon_{\text{low}},\, 1 + \varepsilon_{\text{high}} \right), \quad \rho_{i,t}(\theta) = \frac{\pi_\theta(a_{i,t} \mid s, a_{i,<t})}{\pi_{\theta_{\text{old}}}(a_{i,t} \mid s, a_{i,<t})}. \qquad{(43)}\]
The key difference from PPO/GRPO is subtle but important: clipping the weight (not the objective) means every token still receives a gradient signal proportional to its advantage—the weight just bounds how much that signal is amplified or suppressed by the importance ratio. This is a bias-variance tradeoff: clipping weights introduces bias but controls variance and, critically, avoids dropping token gradients entirely.
Both CISPO and GSPO were developed by organizations pushing the limits of applying RL on large-scale MoE models, which are known for their numerical issues. The papers highlight how the per-token importance sampling ratios are unstable and can add substantial variance to the gradients, mitigating learning. This can make these algorithms particularly impactful on large-scale models, but less studied and beneficial within smaller, academic experiments.
CISPO also allows asymmetric clipping bounds (\(\varepsilon_{\text{low}} \neq \varepsilon_{\text{high}}\)), similar to DAPO’s “clip-higher” modification discussed later in this chapter, which can encourage exploration by allowing larger updates for tokens the model wants to upweight. Related work includes Tapered Off-Policy REINFORCE (TOPR) [17], which also clips IS weights directly (like CISPO) rather than clipping within the objective (like PPO/GRPO), but operates at the sequence level (like GSPO) and uses asymmetric clipping based on reward sign—applying no IS correction for positive rewards while clipping ratios to \([0, 1]\) for negative rewards—enabling stable off-policy learning.
Implementation
Compared to the original Deep RL literature where many of these algorithms were developed, implementing RL for optimizing language models or other large AI models requires many small implementation details. In this section, we highlight some key factors that differentiate the implementations of popular algorithms.
There are many other small details that go into this training. For
example, when doing RLHF with language models a crucial step is
generating text that will then be rated by the reward model. Under
normal circumstances, the model should generate an end-of-sequence
(EOS) token indicating it finished generating, but a common practice
is to put a hard cap on generation length to efficiently utilize
infrastructure. A failure mode of RLHF is that the model is regularly
truncated in its answers, driving the ratings from the reward model
out-of-distribution and to unpredictable scores. The solution to this
is to only run reward model scoring on the
eos_token, and to otherwise assign a penalty to the model
for generating too long.
The popular open-source tools for RLHF have a large variance in implementation details across the algorithms (see table 10 in [18]). Some decisions not covered here include:
- Value network initialization: The internal learned value network used by PPO and other similar algorithms can be started from a different model of the same architecture or randomly selected weights. This can have a large impact on performance. The standard established in InstructGPT [19] (and re-used in Tülu 3 for its work on RLVR [20]) is to initialize the value network from the reward model used during RLHF. Others have used the previous checkpoint to RLHF training (normally an SFT model) with a value head appened randomly initialized, or fully re-initialized language models (less common as it will take longer for RLHF to converge, but possible).
- Reward normalization, reward whitening, and/or advantage whitening: Normalization bounds all the values from the RM (or environment) to be between 0 and 1, which can help with learning stability. Whitening goes further by transforming rewards or advantage estimates to have zero mean and unit variance, providing an even stronger boost to stability.
- Different KL estimators: With complex language models, precisely computing the KL divergence between models can be complex, so multiple approximations are used to substitute for an exact calculation [21].
- KL controllers: Original implementations of PPO and related algorithms had dynamic controllers that targeted specific KLs and changed the penalty based on recent measurements. Most modern RLHF implementations use static KL penalties, but this can also vary.
For more details on implementation details for RLHF, see [22]. For further information on the algorithms, see [23].
Policy Gradient Basics
A simple implementation of policy gradient, using advantages to estimate the gradient to prepare for advanced algorithms such as PPO and GRPO follows:
pg_loss = -advantages * ratioRatio here is the (per-token) probability ratio (often computed from a log-probability difference) of the new policy model probabilities relative to the reference model.
In order to understand this equation, it is good to understand different cases that can fall within a batch of updates. Remember that we want the loss to decrease as the model gets better at the task.
Case 1: Positive advantage, so the action was better than the expected value of the state. We want to reinforce this. In this case, the model will make this more likely with the negative sign. To do so, it’ll increase the logratio. A positive logratio, or sum of log probabilities of the tokens, means that the model is more likely to generate those tokens.
Case 2: Negative advantage, so the action was worse than the expected value of the state. This follows very similarly. Here, the loss will be positive if the new model was more likely, so the model will try to make it so the policy parameters make this completion less likely.
Case 3: Zero advantage, so no update is needed. The loss is zero, don’t change the policy model.
Loss Aggregation
The question when implementing any policy gradient algorithm with language models is: How do you aggregate per-token losses into a final scalar loss? Given per-token losses \(\ell_{i,t}\) for sample \(i\) at token \(t\), with completion lengths \(|a_i|\) and batch size \(B\), there are three main strategies:
Strategy 1: Per-sequence normalization (standard GRPO; also used in some PPO implementations)
\[L = \frac{1}{B} \sum_{i=1}^{B} \frac{1}{|a_i|} \sum_{t=1}^{|a_i|} \ell_{i,t}\qquad{(44)}\]
Each sequence contributes equally to the batch loss, regardless of length. In code:
# Strategy 1: Per-sequence normalization
sequence_loss = ((per_token_loss * completion_mask).sum(dim=1) / \
completion_mask.sum(dim=1)).mean()Strategy 2: Per-token normalization (DAPO [24])
\[L = \frac{\sum_{i=1}^{B} \sum_{t=1}^{|a_i|} \ell_{i,t}}{\sum_{i=1}^{B} |a_i|}\qquad{(45)}\]
Each token contributes equally; longer sequences have proportionally more influence on the gradient. In code:
# Strategy 2: Per-token normalization
token_loss = ((per_token_loss * completion_mask).sum() / \
completion_mask.sum())Strategy 3: Fixed-length normalization (Dr. GRPO [9])
\[L = \frac{1}{B} \sum_{i=1}^{B} \frac{1}{L_{\max}} \sum_{t=1}^{|a_i|} \ell_{i,t}\qquad{(46)}\]
Normalizes by max sequence length \(L_{\max}\), equalizing the per-token scale across sequences while still letting longer sequences contribute more total gradient because they contain more active tokens. In code:
# Strategy 3: Fixed-length normalization
fixed_len_loss = ((per_token_loss * completion_mask).sum(dim=1) / \
L_max).mean()Where \(L_{\max}\) is typically a global constant during the entire training procedure, which specifies the maximum number of generation tokens.
Note that completion_mask in the code above is a
matrix of 1s and 0s, where the prompt tokens are masked out (0s)
because we don’t want the model to learn from predicting prompt
tokens.
Why does this matter?
Intuitively, per-sequence normalization (Strategy 1) seems best since we care about outcomes, not individual tokens. However, this introduces subtle biases based on sequence length, which can cause the model to overthink of down-weight strategies that naturally need to use more tokens, depending on the direction of the bias. Consider two sequences of different lengths with per-token losses:
seq_1_losses = [1, 1, 1, 1, 10] # 5 tokens, mean = 2.8
seq_2_losses = [1, 1, 1, 1, 1, 1, 1, 1, 1, 10] # 10 tokens, mean = 1.9With Strategy 1 (per-sequence): The batch loss is \((2.8 + 1.9)/2 = 2.35\), and crucially, each token in the short sequence receives a larger gradient than tokens in the long sequence.
With Strategy 2 (per-token): The batch loss is \((14 + 19)/15 = 2.2\), and all tokens receive equal gradient magnitude.
With Strategy 3 (fixed-length with \(L_{\max}=10\)): The short sequence contributes \(1.4\) and the long sequence contributes \(1.9\), balancing per-token gradients while still weighting by sequence.
For a more complete example showing how these strategies affect gradients, see the script below.
from typing import Optional
import torch
def masked_mean(values: torch.Tensor, mask: torch.Tensor, axis: Optional[int] = None) -> torch.Tensor:
"""Compute mean of tensor with masked values."""
if axis is not None:
return (values * mask).sum(axis=axis) / mask.sum(axis=axis)
else:
return (values * mask).sum() / mask.sum()
def masked_sum(
values: torch.Tensor,
mask: torch.Tensor,
axis: Optional[int] = None,
constant_normalizer: float = 1.0,
) -> torch.Tensor:
"""Compute sum of tensor with masked values. Use a constant to normalize."""
if axis is not None:
return (values * mask).sum(axis=axis) / constant_normalizer
else:
return (values * mask).sum() / constant_normalizer
ratio = torch.tensor([
[1., 1, 1, 1, 1, 1, 1,],
[1, 1, 1, 1, 1, 1, 1,],
], requires_grad=True)
advs = torch.tensor([
[2, 2, 2, 2, 2, 2, 2,],
[2, 2, 2, 2, 2, 2, 2,],
])
masks = torch.tensor([
# generation 1: 4 tokens
[1, 1, 1, 1, 0, 0, 0,],
# generation 2: 7 tokens
[1, 1, 1, 1, 1, 1, 1,],
])
max_gen_len = 7
masked_mean_result = masked_mean(ratio * advs, masks, axis=1)
masked_mean_token_level = masked_mean(ratio, masks, axis=None)
masked_sum_result = masked_sum(ratio * advs, masks, axis=1, constant_normalizer=max_gen_len)
print("masked_mean", masked_mean_result)
print("masked_sum", masked_sum_result)
print("masked_mean_token_level", masked_mean_token_level)
# masked_mean tensor([2., 2.], grad_fn=<DivBackward0>)
# masked_sum tensor([1.1429, 2.0000], grad_fn=<DivBackward0>)
# masked_mean_token_level tensor(1., grad_fn=<DivBackward0>)
masked_mean_result.mean().backward()
print("ratio.grad", ratio.grad)
ratio.grad.zero_()
# ratio.grad tensor([[0.2500, 0.2500, 0.2500, 0.2500, 0.0000, 0.0000, 0.0000],
# [0.1429, 0.1429, 0.1429, 0.1429, 0.1429, 0.1429, 0.1429]])
masked_sum_result.mean().backward()
print("ratio.grad", ratio.grad)
ratio.grad.zero_()
# ratio.grad tensor([[0.1429, 0.1429, 0.1429, 0.1429, 0.0000, 0.0000, 0.0000],
# [0.1429, 0.1429, 0.1429, 0.1429, 0.1429, 0.1429, 0.1429]])
masked_mean_token_level.mean().backward()
print("ratio.grad", ratio.grad)
# ratio.grad tensor([[0.0909, 0.0909, 0.0909, 0.0909, 0.0000, 0.0000, 0.0000],
# [0.0909, 0.0909, 0.0909, 0.0909, 0.0909, 0.0909, 0.0909]])The output shows that with Strategy 1 (masked_mean),
the short sequence has larger per-token gradients (0.25) than the long
sequence (0.14). Strategies 2 and 3 equalize the per-token gradients
across sequences. Note that these results can vary substantially if
gradient accumulation is used, where the gradients are summed across
multiple minibatches before taking a backward step—in this case, the
balance between shorter and longer sequences can flip.
In practice, the best strategy depends on the specific training setup. Often in RLHF the method with the best numerical stability or the least variance in loss is preferred.
Related: MDP vs Bandit Framing
The choice of loss aggregation connects to a deeper distinction in how we frame the RL problem. The MDP (token-level) view treats each token \(a_t\) as an action with state \(s_t\) being the running prefix. In practice, this is the framing used when we compute token-level advantages with a learned value function \(V(s_t)\) (e.g., GAE [3]) and apply KL penalties per token. PPO with a learned value network is the canonical example [7].
In contrast, the bandit (sequence-level) view treats the whole completion as a single action with one scalar reward \(R\). In code, this means computing a sequence-level advantage \(A_{\text{seq}}\) and broadcasting it to all tokens. RLOO and GRPO-style advantages are often used in this bandit-style setting [6] [1] [12]. Direct alignment methods like DPO and A-LoL also define sequence-level objectives, although they are not policy-gradient estimators [25].
Note that many GRPO implementations use a bandit-style advantage and add a separate per-token KL term in the loss, while many PPO/RLOO implementations fold KL into the reward before computing advantages; both conventions exist in practice.
An example comparison highlighting the two approaches is below:
# === Bandit-style (sequence-level) ===
# One scalar reward per sequence; advantage broadcast to all tokens
reward = torch.tensor([3.0, 1.0]) # (B,) e.g., reward model scores
baseline = reward.mean() # simple baseline (RLOO uses leave-one-out)
advantage_seq = reward - baseline # (B,)
advantages = advantage_seq[:, None].expand(-1, seq_len) # (B, L)
# tensor([[ 1., 1., 1., 1.], <- same advantage for all tokens
# [-1., -1., -1., -1.]])
# === MDP-style (token-level) ===
# Per-token rewards + learned V(s_t); each token gets its own advantage
# (could also use per-token KL shaping, format rewards, or other token-level signals)
advantages = gae(per_token_rewards, values, done_mask, gamma=1.0, lam=0.95)
# tensor([[ 0.2, 0.5, 0.8, 1.5], <- varies by position
# [-0.3, -0.5, -0.8, -1.4]])This framing distinction also explains why the discount factor \(\gamma\) is set to 1.0 in virtually all RLHF implementations. In standard RL, discounting (\(\gamma < 1\)) is essential: it balances the optimization between short-term and long-term reward across a multi-step episode, which is crucial for the agent to learn effective behavior over time. But in the RLHF setting, even when using the token-level MDP view, the inductive bias of the optimization is the quality of the collective completion – the reward signal scores the entire response, not individual tokens. Discounting earlier tokens would arbitrarily down-weight their contribution with no principled justification. As agentic RL settings mature – where models take real multi-step actions such as tool calls, code execution, and web browsing – discounting may become relevant again, since these involve genuinely distinct sequential decisions whose long-term consequences differ.
Asynchronicity
The default implementation for policy-gradient algorithms is what is called on-policy execution, where the actions (generations) taken by the agent (language model) are scored before updating the model. The theoretical derivations of policy-gradient rely on all actions being exactly on-policy where the model is always up to date with the results from the latest trials/roll-outs. In practice, maintaining exact on-policy execution substantially slows training [26]—and perfect synchronization is technically impossible regardless. Therefore, all of the recent empirical results with language models tend to be slightly outside of the theoretical proofs. What happens in practice is designing the algorithms and systems for what actually works.

The common solution used is to constantly run inference and training on separate GPU nodes with software designed to efficiently run both, as shown in the bottom of fig. 8. Common practice in popular open-source RL tools for language models is to use a distributed process management library such as Ray to hand information off between the policy-gradient learning loop and the inference loop using an efficient inference engine, e.g., VLLM. In these setups, the GPUs dedicated to taking the RL steps are called the “learners” and the GPUs dedicated to sampling from the language model are called the “actors” The primary challenges faced when making training more asynchronous are keeping training stable and maintaining learning signal.
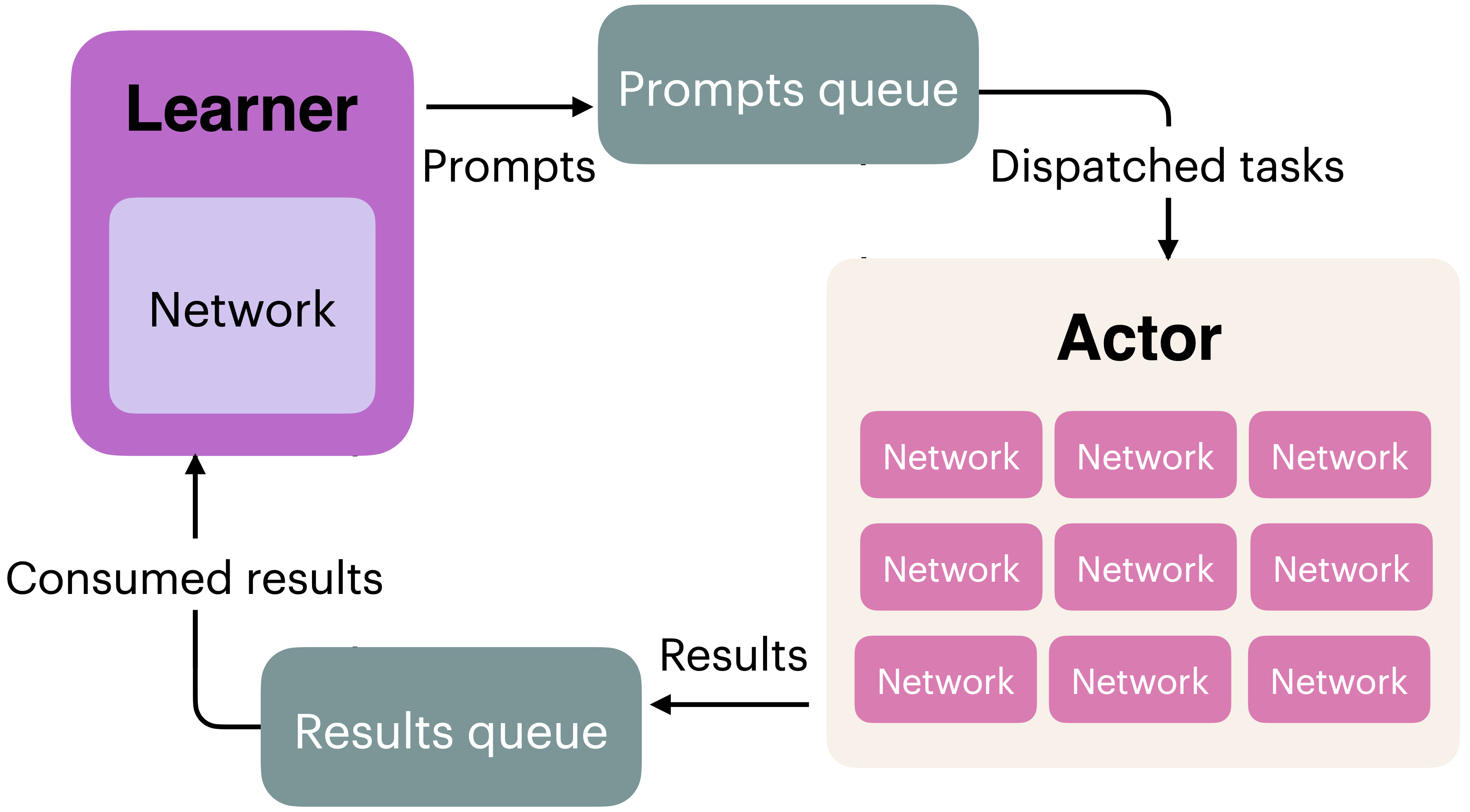
These systems are designed and implemented with the presumption that nearly on-policy data is good enough for stable learning. Here, the generation and update phases can easily be synced to avoid idle compute on either piece of the training system, which would be passing model weights from the learners to the actors in fig. 9. With reasoning models, the extremely long inference characteristics of problems requiring 10K to 100K+ tokens per answer makes the generation of roll-outs a far stronger bottleneck. A common problem when training reasoning models on more synchronous RL infrastructure is that an answer to one prompt in the batch can take substantially more time to generate (either through more tokens or more tool calls), resulting in the majority of the allocated compute being idle until it completes. A second solution to this length mismatch issue, called sequence-level packing, is to stack shorter samples within a batch with clever masking to enable continued roll-outs from the model and better distribute length normalization across samples within a batch. The full complexity of distributed RL infrastructure is out of scope for this book, as it can cause many other subtle issues that slow down training or cause instability.
Following the emergence of these reasoning models, further interest has been taken to make the training and inference loops fully off-policy, where training batches for the policy gradient updates are filled with the most recently completed roll-outs across multiple instances generating answers [27] [28]. Fully asynchronous training would also enable scaling RL training runs across multiple datacenters more easily due to the option of increasing the time between weight syncs between the learner node (taking policy gradient steps) and the actor (trying to solve problems) [29].
Related methods are exploring fully off-policy policy gradient algorithms [30].
Proximal Policy Optimization
There are many, many implementations of PPO available. The core loss computation is shown below. Crucial to stable performance is also the value computation, where multiple options exist (including multiple options for the value model loss).
Note that the reference policy (or old logprobs) here are from the time the generations were sampled and not necessarily the reference policy. The reference policy is only used for the KL distance constraint/penalty.
# B: Batch Size, L: Sequence Length, G: Num of Generations
# Apply KL penalty to rewards
rewards = rewards - self.beta * per_token_kl # Shape: (B*G, L)
# Get value predictions
values = value_net(completions) # Shape: (B*G, L)
# Compute returns via backward pass (gamma typically 1.0 for LM RLHF)
# Mask rewards to avoid padding tokens (which may have KL penalties) leaking into returns
returns = torch.zeros_like(rewards)
running = torch.zeros(rewards.shape[0], device=rewards.device, dtype=rewards.dtype)
for t in reversed(range(rewards.shape[1])):
# Zero out padding: only accumulate rewards/returns for valid completion tokens
running = (rewards[:, t] + self.gamma * running) * completion_mask[:, t]
returns[:, t] = running
# Compute advantages: A_t = G_t - V(s_t)
advantages = returns - values.detach() # Shape: (B*G, L)
# Note: We detach the value network here to not update the parameters of
# the value function when computing the policy-gradient loss
# Normalize advantages (optional but stable)
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
# Compute probability ratio between new and old policies
ratio = torch.exp(new_per_token_logps - per_token_logps) # Shape: (B*G, L)
# PPO clipping objective
eps = self.cliprange # e.g. 0.2
pg_losses1 = -advantages * ratio # Shape: (B*G, L)
pg_losses2 = -advantages * torch.clamp(ratio, 1.0 - eps, 1.0 + eps) # Shape: (B*G, L)
pg_loss_max = torch.max(pg_losses1, pg_losses2) # Shape: (B*G, L)
# Value function loss: predict returns
vf_loss = 0.5 * ((returns - values) ** 2) # Shape: (B*G, L)
# Combine policy and value losses
per_token_loss = pg_loss_max + self.vf_coef * vf_loss # Shape: (B*G, L)
# Apply completion mask and compute final loss
loss = ((per_token_loss * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean()
# Scalar
# Compute metrics for logging
with torch.no_grad():
# Compute clipping fraction
clip_frac = ((pg_losses2 > pg_losses1).float() * completion_mask).sum() / completion_mask.sum()
# Compute approximate KL
approx_kl = (0.5 * ((new_per_token_logps - per_token_logps)**2) * completion_mask).sum() / completion_mask.sum()
# Compute value loss for logging
value_loss = vf_loss.mean()The core piece to understand with PPO is how the policy gradient loss is updated. Focus on these three lines:
pg_losses1 = -advantages * ratio # Shape: (B*G, L)
pg_losses2 = -advantages * torch.clamp(ratio, 1.0 - eps, 1.0 + eps) # Shape: (B*G, L)
pg_loss_max = torch.max(pg_losses1, pg_losses2) # Shape: (B*G, L)pg_losses1 is the vanilla advantage-weighted policy
gradient loss. pg_losses2 applies the same formula but
with the probability ratio clamped to the range \([1-\varepsilon, 1+\varepsilon]\),
limiting how much the policy can change in a single update.
The key insight is taking torch.max of the two losses.
Because we’re minimizing a negative loss (recall the negative
sign in front of advantages), taking the maximum selects the more
pessimistic gradient—the one that produces a smaller policy update.
When the advantage is positive (good action), clipping prevents the
policy from increasing that action’s probability too aggressively.
When the advantage is negative (bad action), clipping prevents
over-correction in the other direction.
By clamping the log-probability ratio, PPO bounds how far the policy can drift from the version that generated the training data, stabilizing learning without requiring an explicit trust region computation.
The code above also shows PPO learning a value function alongside the policy, which adds implementation complexity, but the clipped objective is the core mechanism.
PPO/GRPO simplification with 1 gradient step per sample (no clipping)
PPO (and GRPO) implementations can be handled much more elegantly if the hyperparameter “number of gradient steps per sample” is equal to 1. Many typical values for this are from 2-4 or higher. In the main PPO or GRPO equations, see eq. 27, the “reference” policy is the previous parameters – those used to generate the completions or actions. Thus, if only one gradient step is taken, \(\pi_\theta = \pi_{\theta_{\text{old}}}\), and the update rule reduces to the following (the notation \([]_\nabla\) indicates a stop gradient):
\[J(\theta) = \frac{1}{G}\sum_{i=1}^G \left(\frac{\pi_\theta(a_i|s)}{\left[\pi_{\theta}(a_i|s)\right]_\nabla}A_i - \beta \mathcal{D}_{\text{KL}}(\pi_\theta||\pi_{\text{ref}})\right). \qquad{(47)}\]
This leads to PPO or GRPO implementations where the second policy gradient and clipping logic can be omitted, making the optimizer far closer to standard policy gradient.
Group Relative Policy Optimization
The DeepSeekMath paper describes some implementation details of GRPO that differ from PPO [12], especially if comparing to a standard application of PPO from Deep RL rather than language models. For example, the KL penalty within the RLHF optimization (recall the KL penalty is also used when training reasoning models on verifiable rewards without a reward model) is applied directly in the loss update rather than to the reward function. Where the standard KL penalty application for RLHF is applied as \(r=r_\theta - \beta \mathcal{D}_{\text{KL}}\), the GRPO implementation is along the lines of:
\[ L = L_{\text{policy gradient}} + \beta * \mathcal{D}_{\text{KL}} \qquad{(48)}\]
Though, there are multiple ways to implement this. Traditionally, the KL distance is computed with respect to each token in the completion to a prompt \(s\). For reasoning training, multiple completions are sampled from one prompt, and there are multiple prompts in one batch, so the KL distance will have a shape of [B, L, N], where B is the batch size, L is the sequence length, and N is the number of completions per prompt.
Putting it together, using the first loss accumulation, the pseudocode can be written as below.
# B: Batch Size, L: Sequence Length, G: Number of Generations
# Compute grouped-wise rewards # Shape: (B,)
mean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1)
std_grouped_rewards = rewards.view(-1, self.num_generations).std(dim=1)
# Normalize the rewards to compute the advantages
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
std_grouped_rewards = std_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
# Shape: (B*G,)
# Compute advantages
advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-4)
advantages = advantages.unsqueeze(1)
# Shape: (B*G, 1)
# Compute probability ratio between new and old policies
ratio = torch.exp(new_per_token_logps - per_token_logps) # Shape: (B*G, L)
# PPO clipping objective
eps = self.cliprange # e.g. 0.2
pg_losses1 = -advantages * ratio # Shape: (B*G, L)
pg_losses2 = -advantages * torch.clamp(ratio, 1.0 - eps, 1.0 + eps) # Shape: (B*G, L)
pg_loss_max = torch.max(pg_losses1, pg_losses2) # Shape: (B*G, L)
# important to GRPO -- PPO applies this in reward traditionally
# Combine with KL penalty
per_token_loss = pg_loss_max + self.beta * per_token_kl # Shape: (B*G, L)
# Apply completion mask and compute final loss
loss = ((per_token_loss * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean()
# Scalar
# Compute core metric for logging (KL, reward, etc. also logged)
with torch.no_grad():
# Compute clipping fraction
clip_frac = ((pg_losses2 > pg_losses1).float() * completion_mask).sum() / completion_mask.sum()
# Compute approximate KL
approx_kl = (0.5 * ((new_per_token_logps - per_token_logps)**2) * completion_mask).sum() / completion_mask.sum()For more details on how to interpret this code, see the PPO section above. The core differences from the PPO example are:
- Advantage computation: GRPO normalizes rewards relative to the group (mean and std across generations for the same prompt) rather than using a learned value function as baseline.
- No value network: GRPO removes the value model
entirely, eliminating
vf_lossand the associated complexity. - KL penalty placement: GRPO adds the KL penalty directly to the loss rather than subtracting it from the reward (this is the standard implementation, but more versions exist on how the KL is applied).
RLOO vs. GRPO
The advantage updates for RLOO follow very closely to GRPO, highlighting the conceptual similarity of the algorithm when taken separately from the PPO style clipping and KL penalty details. Specifically, for RLOO, the advantage is computed relative to a baseline that is extremely similar to that of GRPO – the completion reward relative to the others for that same question. Concisely, the RLOO advantage estimate follows as (expanded from TRL’s implementation):
# rloo_k --> number of completions per prompt
# rlhf_reward --> Initially a flat tensor of total rewards for all completions. Length B = N x k
rlhf_reward = rlhf_reward.reshape(rloo_k, -1) #
# Now, Shape: (k, N), each column j contains the k rewards for prompt j.
baseline = (rlhf_reward.sum(0) - rlhf_reward) / (rloo_k - 1)
# baseline --> Leave-one-out baseline rewards. Shape: (k, N)
# baseline[i, j] is the avg reward of samples i' != i for prompt j.
advantages = rlhf_reward - baseline
# advantages --> Same Shape: (k, N)
advantages = advantages.flatten() # Same shape as original tensorThe rest of the implementation details for RLOO follow the other trade-offs of implementing policy-gradient.
Auxiliary Topics
In order to master the application of policy-gradient algorithms, there are countless other considerations. Here we consider some of the long-tail of complexities in successfully deploying a policy-gradient RL algorithm.
Comparing Algorithms
Here’s a summary of some of the discussed material (and foreshadowing to coming material on Direct Preference Optimization) when applied to RLHF. Here, on- or off-policy indicates the derivation (where most are applied slightly off-policy in practice). A reference policy here indicates if it is required for the optimization itself, rather than for a KL penalty.
| Method | Type | Reward Model | Value Function | Reference Policy |
|---|---|---|---|---|
| REINFORCE | On-policy | Yes | No | No |
| RLOO | On-policy | Yes | No | No |
| CISPO | On-policy | Yes | No | Yes |
| PPO | On-policy | Yes | Yes | Yes |
| GRPO | On-policy | Yes | No | Yes |
| GSPO | On-policy | Yes | No | Yes |
| DPO | Off-policy | No | No | Yes |
The core loss \(\mathcal{L}(\theta)\) for each method is:
\[\begin{aligned} \textbf{REINFORCE:}\quad & -\frac{1}{T}\sum_{t=1}^{T}\log \pi_\theta(a_t\mid s_t)\,\big(G_t - b(s_t)\big) \\[6pt] \textbf{RLOO:}\quad & -\frac{1}{K}\sum_{i=1}^{K}\sum_t \log \pi_\theta(a_{i,t}\mid s_{i,t})\left(R_i-\frac{1}{K-1}\sum_{j\neq i}R_j\right) \\[6pt] \textbf{CISPO:}\quad & -\sum_{i,t} \mathrm{sg}(\hat{\rho}_{i,t})\, A_{i,t} \log \pi_\theta(a_{i,t}\mid s_{i,t}) \\ & \quad \hat{\rho}_{i,t} = \mathrm{clip}(\rho_{i,t},\, 1-\varepsilon,\, 1+\varepsilon) \\[6pt] \textbf{PPO:}\quad & -\frac{1}{T}\sum_{t=1}^{T}\min\!\big(\rho_t A_t,\ \mathrm{clip}(\rho_t,1-\varepsilon,1+\varepsilon)\, A_t\big) \\ & \quad \rho_t = \frac{\pi_\theta(a_t\mid s_t)}{\pi_{\theta_{\text{old}}}(a_t\mid s_t)} \\[6pt] \textbf{GRPO:}\quad & -\frac{1}{G}\sum_{i=1}^{G}\min\!\big(\rho_i A_i,\ \mathrm{clip}(\rho_i,1-\varepsilon,1+\varepsilon)\, A_i\big) \\ & \quad \rho_i = \frac{\pi_\theta(a_i\mid s)}{\pi_{\theta_{\text{old}}}(a_i\mid s)},\quad A_i = \frac{r_i-\mathrm{mean}(r_{1:G})}{\mathrm{std}(r_{1:G})} \\[6pt] \textbf{GSPO:}\quad & -\frac{1}{G}\sum_{i=1}^{G}\min\!\big(\rho_i A_i,\ \mathrm{clip}(\rho_i,1-\varepsilon,1+\varepsilon)\, A_i\big) \\ & \quad \rho_i = \left(\frac{\pi_\theta(a_i\mid s)}{\pi_{\theta_{\text{old}}}(a_i\mid s)}\right)^{1/|a_i|} \\[6pt] \textbf{DPO:}\quad & -\mathbb{E}_{(x,y^{w},y^{l})}\!\left[\log \sigma\!\big(\beta[\Delta\log \pi_\theta(x)-\Delta\log \pi_{\mathrm{ref}}(x)]\big)\right] \end{aligned}\]
Generalized Advantage Estimation (GAE)
Generalized Advantage Estimation (GAE) is an alternate method to compute the advantage for policy gradient algorithms [3] that better balances the bias-variance tradeoff. Traditional single-step advantage estimates can introduce too much bias, while using complete trajectories can suffer from high variance. GAE computes an exponentially-weighted average of multi-step advantage estimates, where the \(\lambda\) hyperparameter controls the bias-variance tradeoff—ranging from single-step TD (\(\lambda=0\)) to full trajectory returns (\(\lambda=1\)); \(\lambda=0.95\) is a common default for LLM fine-tuning.
Advantage estimates can take many forms, but we can define a \(n\) step advantage estimator (similar to the TD residual at the beginning of the chapter) as follows:
\[ \hat{A}_t^{(n)} = \begin{cases} r_t + \gamma V(s_{t+1}) - V(s_t), & n = 1 \\ r_t + \gamma r_{t+1} + \gamma^2 V(s_{t+2}) - V(s_t), & n = 2 \\ \vdots \\ r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \cdots - V(s_t), & n = \infty \end{cases} \qquad{(49)}\]
Here a shorter \(n\) will have lower variance but higher bias as we are attributing more learning power to each trajectory – it can overfit. GAE attempts to generalize this formulation into a weighted multi-step average instead of a specific \(n\). To start, we must define the temporal difference (TD) residual of predicted value.
\[ \delta_t^V = r_t + \gamma V(s_{t+1}) - V(s_t) \qquad{(50)}\]
To utilize this, we introduce another variable \(\lambda\) as the GAE mixing parameter. This folds into an exponential decay of future advantages we wish to estimate:
\[ \begin{array}{l} \hat{A}_t^{GAE(\gamma,\lambda)} = (1-\lambda)(\hat{A}_t^{(1)} + \lambda\hat{A}_t^{(2)} + \lambda^2\hat{A}_t^{(3)} + \cdots) \\ = (1-\lambda)(\delta_t^V + \lambda(\delta_t^V + \gamma\delta_{t+1}^V) + \lambda^2(\delta_t^V + \gamma\delta_{t+1}^V + \gamma^2\delta_{t+2}^V) + \cdots) \\ = (1-\lambda)(\delta_t^V(1 + \lambda + \lambda^2 + \cdots) + \gamma\delta_{t+1}^V(\lambda + \lambda^2 + \cdots) + \cdots) \\ = (1-\lambda)(\delta_t^V\frac{1}{1-\lambda} + \gamma\delta_{t+1}^V\frac{\lambda}{1-\lambda} + \cdots) \\ = \sum_{l=0}^{\infty}(\gamma\lambda)^l\delta_{t+l}^V \end{array} \qquad{(51)}\]
Intuitively, this can be used to average multi-step estimates of Advantage in an elegant fashion. An example implementation is shown below:
# GAE (token-level) for LM RLHF
#
# B: Batch Size
# L: Length
# Inputs:
# rewards: (B, L) post-KL per-token rewards
# values: (B, L) current V_theta(s_t)
# done_mask: (B, L) 1.0 at terminal token (EOS or penalized trunc), else 0.0
# gamma: float (often 1.0),
# lam (short for lambda): float in [0,1]
# (Padding beyond terminal should have rewards=0, values=0)
B, L = rewards.shape
advantages = torch.zeros_like(rewards)
next_v = torch.zeros(B, device=rewards.device, dtype=rewards.dtype)
gae = torch.zeros(B, device=rewards.device, dtype=rewards.dtype)
for t in reversed(range(L)):
not_done = 1.0 - done_mask[:, t]
delta = rewards[:, t] + gamma * not_done * next_v - values[:, t]
gae = delta + gamma * lam * not_done * gae
advantages[:, t] = gae
next_v = values[:, t]
targets = advantages + values # y_t for value regression
advantages = advantages.detach() # for policy lossThe backward loop accumulates temporal-difference (TD) errors
(\(\delta_t = r_t + \gamma V(s_{t+1}) -
V(s_t)\)), which measure how much better or worse the actual
outcome was compared to the value function’s prediction, with
exponential decay \((\gamma\lambda)^l\). At terminal tokens,
not_done=0 prevents bootstrapping from future states and
resets the GAE accumulator, so each episode’s advantages are computed
independently (since the loop runs backward, the terminal token
cleanly stops the exponentially-weighted accumulation at episode
boundaries—this makes the implementation packing-friendly, correctly
handling multiple sequences concatenated into one). The final
targets serve as regression targets for the separate
value function learned outside this GAE loop, while the detached
advantages weight the policy gradient—detached so that
policy updates don’t backpropagate through the value network. In RLHF
for language models, \(\gamma=1.0\)
is common because episodes are short token sequences where
undiscounted credit assignment is preferred (and often all of the
tokens in one).
For further reading, see [31].
Double Regularization
We’ve seen in this chapter two types of regularization. One is built into algorithms like PPO with step-size constraints, and the other is a KL divergence based distance penalty relative to the start of the optimization.
Many popular policy gradient algorithms from Deep Reinforcement Learning, including PPO and its predecessors, originated due to the need to control the learning process of the agent. In RLHF, as discussed extensively in Chapter 15 on Regularization and in Chapter 3 on Training Overview, there is a built-in regularization term via the distance penalty relative to the original policy one is fine-tuning. In this view, a large part of the difference between algorithms like PPO (which have internal step-size regularization) and REINFORCE (which is simpler, and to which PPO reduces under certain hyperparameters) is far less meaningful for fine-tuning language models than training agents from scratch.
In PPO, the objective that handles capping the step-size of the update is known as the surrogate objective. To monitor how much the PPO regularization is impacting updates in RLHF, one can look at the clip fraction variable in many popular implementations, which is the percentage of samples in the batch whose probability ratio falls outside the clipping interval. This is a useful proxy for how often PPO’s regularizer may be active, but not every such sample has zero gradient: the surrogate becomes flat only when the clipped branch is selected, such as positive-advantage samples with ratios above \(1+\varepsilon\) or negative-advantage samples with ratios below \(1-\varepsilon\).
In practice with language models, algorithms like PPO and GRPO are often run with only one gradient step per batch, which means that the PPO-native regularization is never applied (as clipping can only occur within a batch when the policy changes substantially) and the KL distance penalties predominate. However, this is not universal. For example, DAPO uses 16 gradient steps per batch [24], and Tülu 3 uses 4 PPO update iterations per batch for 8B and 70B models but reduces to 1 for 405B to maintain training stability [20].
Further Reading
As RLHF has cemented itself at the center of modern post-training, other policy-gradient RL algorithms and RL algorithms generally have been proposed to improve the training process, but they have not had a central role in governing best practices. Examples for further reading include:
- Pairwise Proximal Policy Optimization (P3O; Wu et al., 2023) [32] uses pairwise data directly in a PPO-style policy update without learning an intermediate reward model.
- Soft Adaptive Policy Optimization (SAPO) [33] replaces hard PPO/GRPO-style clipping with smooth, temperature-controlled gating, aiming for a continuous trust region that preserves near-on-policy learning signal while down-weighting off-policy tokens.
- Off-policy policy-gradient algorithms could enable further asynchronous training, such as Contrastive Policy Gradient (CoPG) [34] (a generalization of the direct alignment algorithm IPO and vanilla policy gradient), which was used by Cohere for their Command A model [35].
- Other implementations of REINFORCE algorithms have been designed for language models, such as ReMax [36], which implements a baseline normalization designed specifically to accommodate the sources of uncertainty from reward model inference.
- Some foundation models, such as Apple Intelligence Foundation Models [37] or Kimi k1.5 reasoning model [38], have used variants of Mirror Descent Policy Optimization (MDPO) [39]. Research is still developing further on the fundamentals here [40], but Mirror Descent is an optimization method rather than directly a policy gradient algorithm. What is important here is that it is substituted in very similarly to existing RL infrastructure.
- Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO) proposes 4 modifications to GRPO to better suit reasoning language models, where long traces are needed and new, underutilized tokens need to be increased in probability [24]. The changes are: 1, have two different clip hyperparameters, \(\varepsilon_\text{low}\) and \(\varepsilon_\text{high}\), so clipping on the positive side of the logratio can take bigger steps for better exploration; 2, dynamic sampling, which removes all samples with reward = 0 or reward = 1 for all samples in the batch (no learning signal); 3, use the per token loss as discussed above in Implementation: GRPO; and 4, a soft penalty on samples that are too long to avoid trying to learn from truncated answers.
- Value-based Augmented Proximal Policy Optimization (VAPO) [41] combines optimizations from DAPO (including clip-higher, token level policy-gradient, and different length normalization) with insights from Value-Calibrated PPO [42] to pretrain the value function and length-adaptive GAE to show the promise of value base methods relative to GRPO.