Synthetic Data & Distillation
Reinforcement learning from human feedback is deeply rooted in the idea of keeping a human influence on the models we are building. When the first models were trained successfully with RLHF, human data was the only viable way to improve the models in this way.
Humans were the only way to create high enough quality responses to questions for training. Humans were the only way to collect reliable and specific feedback data to train reward models.
As AI models got better, this assumption rapidly broke down. The possibility of synthetic data, which is far cheaper and easier to iterate on, enabled the proliferation of RLHF by lowering the price of experiments and research. This translated into RLHF being the early center of attention in the broader “post-training” approach to shaping models. This chapter provides a cursory overview of how and why synthetic data is replacing or expanding many pieces of the RLHF pipeline.
The Roles of Synthetic Data
One common criticism of synthetic data is model collapse – the idea that repeatedly training on a model’s own generations can progressively narrow the effective training distribution [1]. As diversity drops, rare facts and styles are underrepresented, and small mistakes can be amplified across iterations, leading to worse generalization. In practice, these failures are most associated with self-training on unfiltered, repetitive, single-model outputs; mixing in real/human data, using diverse teachers, deduplication, and strong quality filters largely avoids the collapse regime. For today’s frontier training pipelines, evidence suggests synthetic data can, and should, be used at scale without the catastrophic regressions implied by the strongest versions of the collapse story [2] [3].
The leading models need synthetic data to reach the best performance. Synthetic data in modern post-training encompasses many pieces of training – language models are used to generate new training prompts from seed examples [4], modify existing prompts, generate completions to prompts [5], provide AI feedback to create preference data [6], filter completions [7], and much more. Synthetic data is key to post-training.
The ability for synthetic data to be impactful to this extent emerged with GPT-4 class models. With early language models, such as Llama 2 and GPT-3.5-Turbo, the models were not reliable enough in generating or supervising data pipelines. Within 1-2 years, language models were far superior to humans for generating answers. In the transition from GPT-3.5 to GPT-4 class models, the ability for models to perform LLM-as-a-judge tasks also emerged. GPT-4 or better models are far more robust and consistent in generating feedback or scores with respect to a piece of content.
Through the years since ChatGPT’s release at the end of 2022, we’ve seen numerous, impactful synthetic datasets. These include UltraFeedback [6], the first prominent synthetic preference dataset that kickstarted the DPO revolution; Stanford Alpaca, one of the first chat-style fine-tuning datasets, in 2023; skill-focused (e.g. math, code, instruction-following) synthetic datasets in Tülu 3 [8]; and OpenThoughts 3 and many other synthetic reasoning datasets in 2025 for training thinking models [9]. Most of the canonical references for getting started with industry-grade post-training today involve datasets like Tülu 3 or OpenThoughts 3 above, where quickstart guides often start with smaller, simpler datasets like Alpaca due to far faster training.
A large change is also related to dataset size, where fine-tuning datasets have grown in the number of prompts, where Alpaca is 52K, OpenThoughts and Tülu 3 are 1M+ samples, and in the length of responses. Longer responses and more prompts result in the Alpaca dataset being on the order of 10M training tokens, where Tülu is 50X larger at about 500M, and OpenThoughts 3 is bigger still, on the order of 10B tokens.
Throughout this transition, synthetic data has not replaced human data uniformly across the pipeline. For instruction data (SFT), synthetic generation has largely won – distillation from stronger models now produces higher quality completions than most human writers can provide at scale (with some exceptions in the hardest frontier reasoning problems). For preference data in RLHF, the picture is more mixed: academic work shows synthetic preference data performs comparably, yet frontier labs still treat human preference data as a competitive moat. For evaluation, the split takes a different flavor: LLM-as-a-judge scales the scoring of model outputs cost-effectively, but the underlying benchmarks and ground-truth labels still require human creation. The pattern is that synthetic data dominates where models exceed human reliability, while humans remain essential at capability frontiers, for establishing ground truth, and for guiding training.
Distillation with Synthetic Data
The term distillation has been the most powerful form of discussion around the role of synthetic data in language models. Distillation as a term comes from a technical definition of teacher-student Knowledge Distillation (KD) from the deep learning literature [10].
Distillation colloquially refers to using the outputs from a stronger model to train a smaller model.
 In post-training, this general notion of distillation takes two common forms:
In post-training, this general notion of distillation takes two common forms:
- As a data engine to use across wide swaths of the post-training process: Completions for instructions, preference data (or Constitutional AI), or verification for RL.
- To transfer specific skills from a stronger model to a weaker model, which is often done for specific skills such as mathematical reasoning or coding.
The first strategy has grown in popularity as language models evolved to be more reliable than humans at writing answers to a variety of tasks. GPT-4 class models expanded the scope of this to use distillation of stronger models for complex tasks such as math and code (as mentioned above). Here, distillation motivates having a model suite where often a laboratory will train a large internal model, such as Claude Opus or Gemini Ultra, which is not released publicly and just used internally to make stronger models. With open models, common practice is to distill training data from closed API models into smaller, openly available weights [11]. Within this, curating high-quality prompts and filtering responses from the teacher model is crucial to maximize performance.
Transferring specific skills into smaller language models uses the same principles of distillation – get the best data possible for training. Here, many papers have studied using limited datasets from stronger models to improve alignment [12], mathematical reasoning [13] [14], and test-time scaling [15].
The synthetic-data methods in the rest of this chapter are all ways of crafting data recipes that use language-model outputs directly inside training pipelines.
The Path to On-Policy, Teacher-Student Distillation
While distillation generally has become a standard approach for post-training language models, a resurgence of interest in the specific sub-area of teacher-student knowledge distillation has accompanied the shift of post-training recipes towards reasoning and agentic models. Examples of leading models trained with new forms of knowledge distillation include Alibaba’s Qwen3 [16], Xiaomi’s MiMo-V2-Flash [17], Zhipu AI’s GLM-5 [18], and DeepSeek-V4-Pro [19].
Distillation belongs in this chapter because many modern uses of synthetic data in post-training are, in practice, distillation-inspired pipelines: a stronger model produces labels, completions, logits, critiques, or other supervision, and a student model is trained on that signal. At the same time, the technical literature on distillation is growing into its own set of post-training methods, especially as on-policy and self-distillation recipes become more common. For now, we cover it here as part of the synthetic-data toolkit, but future versions of this book may warrant a dedicated chapter on distillation as a training tool alongside instruction fine-tuning, reinforcement learning, etc.
Adapting Knowledge-Distillation for LMs
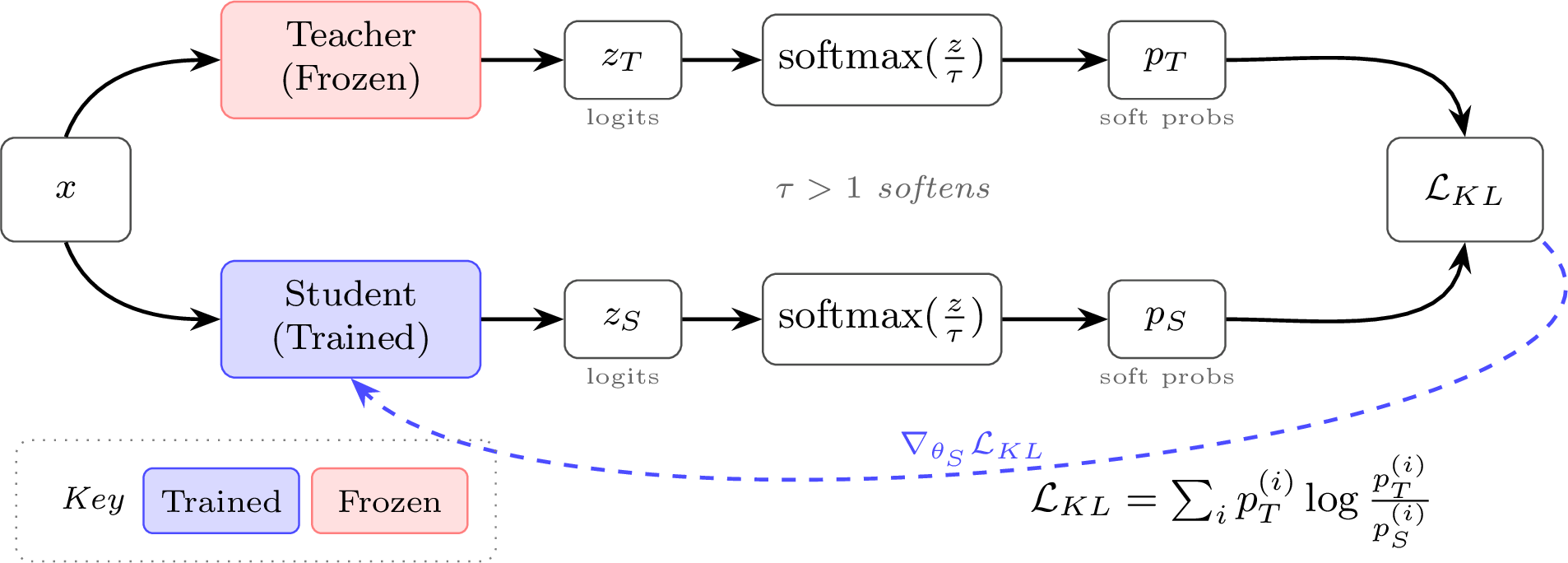
The original literature introduced knowledge distillation specifically as a way to train a student model from an already trained, stronger, and/or bigger teacher network [10]. KD is known as a technique that uses soft training labels, as opposed to the one-hot labels used in standard objectives like next-token prediction with cross-entropy loss. The objectives over soft labels look at the distribution over all possible next tokens or predictions, rather than just whether or not the single predicted token was correct, and train the student distribution to match the teacher distribution.
KD generally can be applied to any deep learning problem, e.g. predicting a single class of an input. In order to apply it specifically to the autoregressive style of language models, the loss can be decomposed to make a per-token distribution-matching loss. In 2016, Kim & Rush applied KD to have a student model learn from sequences generated by a teacher model [20].
Let \(s\) be the source sentence or prompt, \(u = (u_1,\ldots,u_J)\) be a complete output sequence from the teacher model, \(\mathcal{V}\) be the output vocabulary (possible tokens in the tokenizer), \(q\) be the teacher distribution over next-tokens, and \(p\) be the student distribution. We use \(u\) here as a neutral symbol for a complete teacher output sequence, reserving \(a\) for the student-sampled completion/action sequence in the on-policy/RL notation below. Note that their paper calls this word-level distillation, but for modern language models this is best read as per-token distribution matching over the tokenizer vocabulary, since the paper predates modern sub-word tokenizers:
\[ \mathcal{L}_{\mathrm{WORD-KD}} = -\sum_{j=1}^{J}\sum_{k=1}^{|\mathcal{V}|} q(u_j = k \mid s, u_{<j})\log p(u_j = k \mid s, u_{<j}). \qquad{(1)}\]
WORD-KD is an application of the classic, Hinton inspired teacher-student knowledge distillation to a language model. This would generally be done over a static piece of text already in the training corpus.
This has the ordinary cross-entropy form \(-\sum_z q(z)\log p(z)\). At each position \(j\), the teacher distribution \(q\) assigns probability to every possible next token \(k \in \mathcal{V}\), and the student is penalized when its distribution \(p\) puts low probability on tokens the teacher considers likely.
Sequence-level distillation instead treats \(\mathcal{U}\) as the space of possible output sequences and matches the student to the teacher distribution over full sequences. Because the sum over all complete sequences \(u \in \mathcal{U}\) is intractable, requiring summing over an exponential number of potential sequences, Kim & Rush approximate the teacher distribution over sequences with a point mass on a single high-probability teacher output \(\hat{u}\). Here \(\hat{u}\) is a sequence produced by beam search with the teacher model, so \(\hat{u} = \mathrm{BeamSearch}_q(s) \approx \arg\max_{u \in \mathcal{U}} q(u \mid s)\):
\[ \begin{aligned} \mathcal{L}_{\mathrm{SEQ-KD}}(s) = -\sum_{u \in \mathcal{U}} q(u \mid s)\log p(u \mid s) \approx -\log p(\hat{u} \mid s) \\ = -\sum_{j=1}^{|\hat{u}|}\log p(\hat{u}_j \mid s, \hat{u}_{<j}). \end{aligned} \qquad{(2)}\]
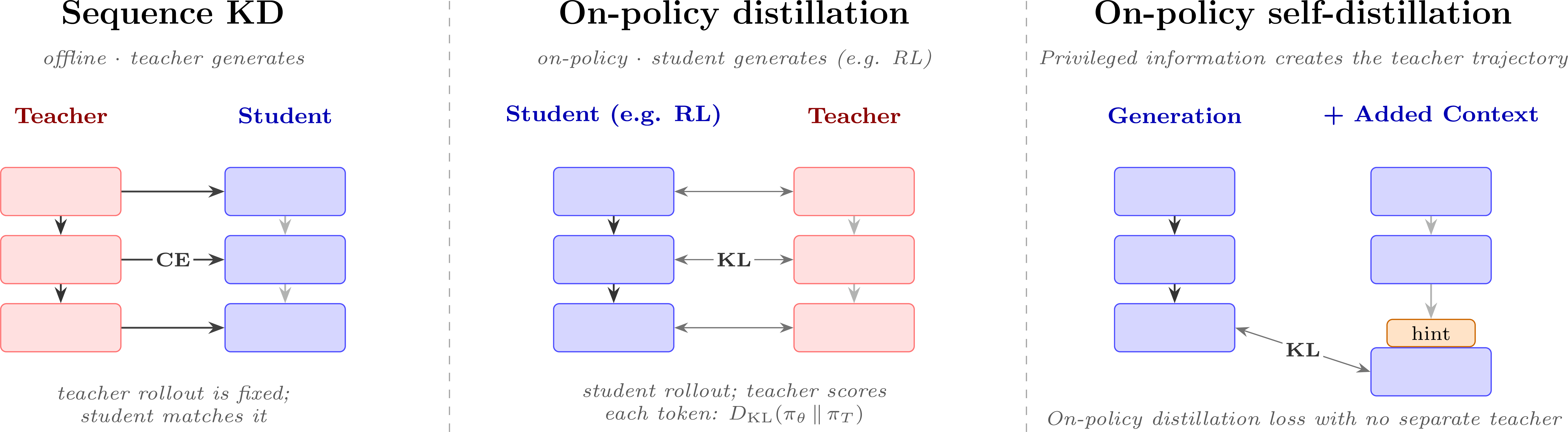
SEQ-KD takes a step towards modern methods, where the teacher model is generating tokens as signal for the student. This is a core step to unlock future styles of on-policy distillation we will see, and is needed to make the computation over all possible sequences tractable. As we transition to the popular variants of KD with modern models, we’ll refer to this style of training as offline KD – as in the generations for training the student model are generated a priori.
Before proceeding, two connections are useful.
First, there was a series of popular models trained with offline KD, such as the classifiers DistilBERT [21] and TinyBERT [22], which combined other improvements in language models with offline distillation (notably, not sequence distillation because these encoder models were not distilled for multi-token autoregressive prediction).
Second, we can make the connection to the thorough coverage of Kullback-Leibler (KL) divergence in Chapter 15, because the cross-entropy objective used above is closely related to KL divergence. For a teacher distribution \(q\) and student distribution \(p\), cross-entropy is defined as
\[ H(q,p) = -\sum_z q(z)\log p(z). \qquad{(3)}\]
This has the same form as eq. 1 and the first term of eq. 2. Cross-entropy also can be decomposed into the entropy of the teacher distribution and a KL divergence:
\[ \begin{aligned} H(q,p) &= H(q) + D_{\mathrm{KL}}(q\|p) \\ &= -\sum_z q(z)\log q(z) + \sum_z q(z)\log\frac{q(z)}{p(z)}. \end{aligned} \qquad{(4)}\]
The first term, \(H(q)\), only depends on the teacher. Thus, when the teacher is fixed and the source of training data, minimizing cross-entropy is equivalent to minimizing the forward KL, \(D_{\mathrm{KL}}(q\|p)\), from teacher to student. This is the KL direction used by offline KD and SFT-like training.
From Offline to On-Policy Distillation
These offline KD algorithms had a few limitations that motivated on-policy variants. The offline nature of the learning meant that the student models could suffer from a distribution mismatch between the teacher model and sequences generated by the student at inference time. For example, the forward KL objective can push student models to overestimate low-probability regions of the teacher distribution. Together, these issues were an opening for on-policy distillation (OPD).
This train-test gap is known as exposure bias [23] [24]. Offline KD samples teacher trajectories \(u \sim \pi_T(\cdot \mid s)\) and minimizes the per-token KL on the resulting prefixes,
\[ \mathcal{L}_{\mathrm{KD}}(\theta) = \mathbb{E}_{s \sim \mathcal{D},\, u \sim \pi_T(\cdot \mid s)} \sum_t D_{\mathrm{KL}}\!\left( \pi_T(\cdot \mid s, u_{<t}) \;\|\; \pi_\theta(\cdot \mid s, u_{<t}) \right). \qquad{(5)}\]
At inference the student instead rolls out under its own policy, so the quantity that actually matters is the expected task loss along its own trajectories,
\[ \mathcal{L}_{\mathrm{eval}}(\theta) = \mathbb{E}_{s \sim \mathcal{D}_{\mathrm{test}},\, a \sim \pi_\theta(\cdot \mid s)} \ell_{\mathrm{task}}(s, a) \qquad{(6)}\]
Here, \(\ell_{\mathrm{task}}(s, a)\) denotes any downstream task loss for the completed student response, such as answer incorrectness, failed test cases, or a judge/rubric loss. Exposure bias is the direct consequence of the inequality \(\pi_T(\cdot \mid s) \neq \pi_\theta(\cdot \mid s)\): the prefixes \((s, u_{<t})\) visited during training and the prefixes \((s, a_{<t})\) visited at test time are drawn from different state-visitation distributions, so the student is supervised on a set of states distinct from those it acts on.
The core shift to on-policy distillation is the idea that we can tweak the optimization by sampling from the student model and measuring its distance to the teacher distribution, rather than sampling from the teacher model. MiniLLM noted the need to shift to a reverse KL optimization (we explain intuitively why this target can be better in Chapter 15) and proposed using KD loss functions within an online policy-gradient RL framework [25]. Other concurrent work [26] showed the promise of on-policy KD and connected the iterative process of generating from the student and grading with a teacher to imitation-learning work from the RL literature. To make the connection, one such imitation-learning algorithm, DAgger, iteratively trains an agent that acts in the world with its learned policy and is given feedback from an oracle policy on what action it should have taken, which can then be used to update its policy [27].
The cost of this gap can be quantified through the supervised imitation-learning bound that motivates DAgger. In the original discrete-action setting, suppose the learned policy matches the teacher within an expected per-step action error \(\epsilon\) on the teacher-induced training distribution, where \(\mathbb{I}[\cdot]\) is an indicator that returns 1 when its condition is true and 0 otherwise,
\[ \mathbb{E}_{s_t \sim d_{\pi_T}}\!\left[ \mathbb{I}\!\left(\pi_\theta(s_t) \neq \pi_T(s_t)\right) \right] \leq \epsilon. \qquad{(7)}\]
The supervised imitation-learning analysis [27] shows that the expected loss accumulated along a length-\(L\) trajectory sampled from the student can scale quadratically in \(L\) [24]:
\[ \mathbb{E}_{a \sim \pi_\theta(\cdot \mid s)}\!\left[\sum_{t=1}^{L} \ell\!\left(s, a_{<t}\right)\right] \leq O(\epsilon L^2). \qquad{(8)}\]
For LLMs, this discrete-action bound should be read as an analogy rather than a theoretical guarantee. In practice, LLMs predict full next-token distributions over long horizons, so the 0-1 action-disagreement assumption in eq. 7 does not apply cleanly. Prompts or prefixes map naturally to states and sampled tokens map to actions, but token-level distillation is usually measured with distributional losses such as KL or cross-entropy, so the classic DAgger math does not transfer exactly.
This kind of \(O(\epsilon L^2)\) compounding is especially pronounced for modern LLMs, which routinely generate sequences spanning thousands of tokens. A single suboptimal token shifts the prefix slightly out-of-distribution, and the model, having never seen this perturbed prefix, is more likely to err again, leading to degraded or hallucinatory text. On-policy distillation addresses this by iteratively sampling completions from the current student and supervising them with the teacher at the visited states. The student confronts its own mistakes, receives teacher feedback on the specific out-of-distribution states it visits, and learns recovery behaviors. Under DAgger’s interactive imitation-learning analysis, this iterative procedure can reduce the compounding from \(O(\epsilon L^2)\) to \(O(\epsilon L)\) [27]. For LLMs, this explains the motivation behind OPD: the exact bounds may not carry over cleanly to every token-level distillation setup, but the practical success of on-policy methods supports the underlying intuition.
For on-policy distillation, let \(s\) be a prompt, \(a = (a_1,\ldots,a_L)\) be a completion sampled from the current student policy \(\pi_\theta(\cdot \mid s)\), and let \(s_t = (s, a_{<t})\) be the token-level state at step \(t\). The teacher policy \(\pi_T\) is fixed, so the objective compares the student’s next-token distribution to the teacher’s distribution on states induced by the student. Because the expectation samples from \(\pi_\theta\) and the student distribution is on the left side of \(D_{\mathrm{KL}}(\pi_\theta \| \pi_T)\), this is a reverse-KL objective:
\[ \mathcal{L}_{\mathrm{OPD}}(\theta) = \mathbb{E}_{s, a \sim \pi_\theta(\cdot \mid s)} \sum_t D_{\mathrm{KL}}\left(\pi_\theta(\cdot \mid s_t) \;\|\; \pi_T(\cdot \mid s_t)\right). \qquad{(9)}\]
Here, we have shifted to the expectation notation, as used extensively in Chapter 6, which covers the fundamental RL policy-gradient algorithms, as the optimization is solved by sampling trajectories and numerically estimating the gradient. This shift to the sampling framework acts as a natural transition to modern LLM training infrastructure with RL, which is designed to rapidly alternate between generating tokens from the current policy being trained and taking learning updates.
In fact, recent implementations of OPD take this integration of KD with RL a step further, where the KD distance is taken directly as a reward signal within the RL optimization. A canonical implementation is to substitute the negative per-token contribution to the reverse KL distance as the advantage within an RL algorithm [28]. For a sampled token \(a_t\) at state \(s_t\), the token-level log-probability gap can be written as an advantage-like signal:
\[ A_t^{\mathrm{OPD}} = \log \pi_T(a_t \mid s_t) - \log \pi_\theta(a_t \mid s_t). \qquad{(10)}\]
Using the negative per-token KL contribution turns minimization into a maximization signal: sampled tokens the teacher rates above the student receive positive advantage, and tokens the teacher rates below the student receive negative advantage. The teacher log-prob gap acts like dense token-level feedback, providing potentially more useful learning feedback than the sparse verifiable rewards or reward model outputs.
Modern OPD Variants
This setup can even be expanded further, where multiple teacher models are used to teach one final model or additional information can be inserted into a generation to help a model identify a mistake. To begin, we will cover how to integrate multiple teachers into a single training run. These teachers can be specific specialist models, e.g. for a domain such as math or code, or a previous, intermediate training checkpoint. For each teacher, a contribution weight can be chosen per prompt or task type in the training batch, in order to create Multi-Teacher On-Policy Distillation (MOPD) [17]. For multiple teachers, let \(\pi_{T_k}\) be teacher \(k\) and let \(w_k(s)\) be its prompt-dependent mixture weight (with \(\sum_k w_k(s) = 1\)) within the reverse KL loss:
\[ \mathcal{L}_{\mathrm{MOPD}}(\theta) = \mathbb{E}_{s, a \sim \pi_\theta(\cdot \mid s)} \sum_t \sum_k w_k(s) D_{\mathrm{KL}}\left(\pi_\theta(\cdot \mid s_t) \;\|\; \pi_{T_k}(\cdot \mid s_t)\right). \qquad{(11)}\]
In large-scale post-training, this can enable further scaling of recipes across growing organizations. Multiple groups can work on high-quality expert models, which can serve as teacher models down the line for the final student model, as done for [19] and [17].
There are many ways to combine OPD with other areas investigated in this book, such as using the reverse KL as an advantage in addition to other forms of advantage computation, such as GRPO’s group-level normalization, which enables more complex reward shaping. KD methods are unusual among post-training methods because they often require the student and teacher to share a tokenizer, since the supervision can be per-token feedback from another LLM.
Extended approaches, such as On-Policy Self-Distillation (OPSD), have a language model verify a completion either itself or with external tools to act as a teacher with privileged information, so it can improve its own performance without an explicitly stronger teacher [29] (an overview of OPSD training is shown in fig. 3). For example, Cursor used self-distillation in the form of targeted textual feedback on RL trajectories to train its Composer 2.5 coding model [30], finetuned from Kimi K2.5. What follows is a simplified intuition, as in practice the setup below is combined with other loss functions such as code correctness. In this setup, Cursor has the model review RL trajectories with a judgement prompt that has a list of common bugs. When encountering a bug, the judgement model will modify the generated sequence within RL – inserting a hint for the model to learn from in the future – and then proceed with the distillation loss. This entails a loop of first generating a completion with standard language model generation in RL, then running the judge model and optionally inserting a hint token, and finally generating the logprobs for the new completion to deploy the knowledge distillation loss. The hint in the token-space for the model is enough to help the model correct its own outputs, even when improving at the absolute frontier of performance (there’s meaningful ongoing work on how to best structure and use these hints, often referred to as privileged information [31]).
This leaves on-policy distillation as a core post-training method, useful for combining multiple skills into one general model or pushing the frontier in a specialized deployment.
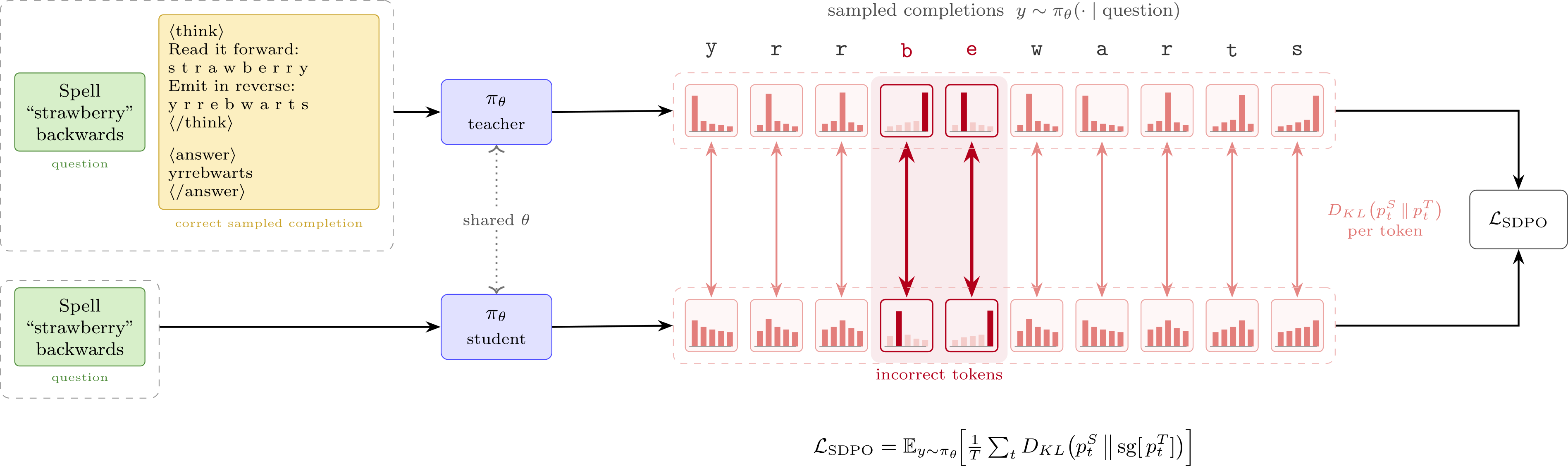
Suggested Experiments
The companion code in code/distillation/ implements SDPO [32], the on-policy self-distillation setup illustrated in fig. 3 (the concurrent OPSD paper [29] is closely related): one policy acts as both the demonstration-conditioned teacher and the question-only student, trained with a per-token reverse KL. It runs on a small string-reversal task, which makes the on-policy distillation loop cheap enough to watch end-to-end on a single GPU.
Run the SDPO string-reversal example.
cd code/ uv run python -m distillation.train --config distillation/configs/sdpo.yamlWatch
reward,loss, andskipped, along with the teacher/student rollout samples printed in the loop. Theskippedcount is the number of polled prompts whose sampled group contained no correct rollout; as the student improves, fewer prompts are skipped andrewardclimbs toward 1.Vary the on-policy knobs. Copy
distillation/configs/sdpo.yamland sweepnum_rollouts,kl_top_k, andprompts_per_stepwhile holding the task fixed. More rollouts per prompt make a correct sibling demonstration easier to find (loweringskipped) at the cost of more generation per step;kl_top_ktrades off how much of the teacher distribution the reverse KL matches against compute.
AI Feedback
Soon after the explosion of growth in RLHF, RL from AI Feedback (RLAIF) emerged as an alternative approach where AIs could approximate the human data piece of the pipeline and accelerate experimentation or progress. AI feedback, generally, is a larger set of techniques for using AI to augment or generate data explaining the quality of a certain input (which can be used in different training approaches or evaluations), and it started with pairwise preferences [33] [34] [35]. There are many motivations to use RLAIF to either entirely replace human feedback or augment it. Within the RLHF process, AI feedback is known most for its role within the preference data collection and the related reward model training phase (of which constitutional AI is a certain type of implementation). In this chapter, we focus on general AI feedback and this specific way of using it in the RLHF training pipeline, and we cover more ways of understanding or using synthetic data later in this book.
As AI feedback matured, its applications expanded beyond simply replacing human preference labels. The same LLM-as-a-judge infrastructure that enabled cheaper preference data collection also enabled scalable evaluation (see Chapter 16), and more recently, rubric-based rewards that extend RL training to domains without verifiable answers – a frontier explored later in this chapter.
Balancing AI and Human Feedback Data
AI models are far cheaper than humans at generating a specific quantity of feedback: as of 2026, a single piece of human preference data costs on the order of $1 or higher (or even above $10 per prompt), whereas AI feedback with a frontier AI model, such as GPT-4o, costs less than $0.01. Beyond this, the cost of human labor remains roughly constant, while the performance of leading models at these tasks continues to increase while price-per-performance decreases. This cost difference opens the market of experimentation with RLHF methods to an entire population of people previously priced out.
Other than price, AI feedback introduces different tradeoffs on performance than human feedback, which are still being investigated in the broader literature. AI feedback is far more predominant in its role in evaluation of the language models that we are training, as its low price allows it to be used across a variety of large-scale tasks where the cost (or time delay) of human data would be impractical. All of these topics are deeply intertwined – AI feedback data will never fully replace human data, even for evaluation, and the quantity of AI feedback for evaluation will far outperform training because far more people are evaluating than training models.
The exact domains and applications – i.e. chat, safety, reasoning, mathematics, etc. – where AI feedback data outperforms human data are not completely established. Some early work in RLAIF shows that AI feedback can completely replace human data, touting it as an effective replacement [33], especially when evaluated solely on chat tasks [6] [36]. Early literature studying RLHF after ChatGPT had narrow evaluation suites focused on the “alignment” of models that act as helpful assistants across a variety of domains (discussed further in Chapter 17). Later work takes a more nuanced picture, where the optimal equilibrium on a broader evaluation set, e.g. including some reasoning tasks, involves routing a set of challenging data points to humans for accurate labeling, while most of the data is sent for AI feedback [37] [38]. Although no studies have focused on the balance between human and AI feedback data for RLHF across broader domains, there are many technical reports that show RLHF generally can improve this broad suite of evaluations, some that use DPO, such as Ai2’s Tülu 3 [8] and Olmo 3 [39], or Hugging Face’s SmolLM 3 [40], and others that use online RLHF pipelines, such as NVIDIA’s work that uses a mix of human preference data from Scale AI and LLM-based feedback (through the HelpSteer line of work [41] [42] [43] [44]): Nemotron Nano 3 [45], Nemotron-Cascade [46], or Llama-Nemotron reasoning models [47].
Overall, although AI feedback and related methods are obviously extremely useful to the field, it is clear that human data has not been completely replaced by these cheaper alternatives. Many hypotheses exist, but whether human data allows finer control of the models in real-world product settings or for newer training methods such as character training (an emerging set of techniques that allow you to precisely control the personality of a model, covered in Chapter 17) has not been studied. For those getting started, AI feedback should be the first attempt, but for pipelines that are scaling to larger operations the eventual transition to include human feedback is likely.
The term RLAIF was introduced in Anthropic’s work Constitutional AI: Harmlessness from AI Feedback [48], which resulted in initial confusion in the AI community over the relationship between the two methods in the title of the paper (Constitutional AI and AI Feedback). Since the release of the Constitutional AI (CAI) paper and the formalization of RLAIF, RLAIF has become a default method within the post-training and RLHF literatures – there are far more examples than one can easily enumerate. The relationship should be understood as CAI was the example that kickstarted the broader field of RLAIF.
A rule of thumb for the difference between human data and AI feedback data is as follows:
- Human data is high-noise and low-bias. This means that collection and filtering of the data can be harder, but when wrangled it’ll provide a very reliable signal.
- Synthetic preference data is low-noise and high-bias. This means that AI feedback data will be easier to start with, but can have tricky, unintended second-order effects on the model that are systematically represented in the data.
This book highlights many academic results showing how one can substitute AI preference data in RLHF workflows and achieve strong evaluation scores [37], but broader industry trends show how the literature of RLHF is separated from more opaque best practices. Across industry, human data is often seen as a substantial moat and a major technical advantage.
Building Specific LLMs for Judgment
As RLAIF methods have become more prevalent, many have wondered if we should be using the same models for generating responses as those for generating critiques or ratings. Specifically, the calibration of the LLM-as-a-judge used has come into question. Several works have shown that LLMs are inconsistent evaluators [49] and prefer their own responses over responses from other models (coined self-preference bias) [50].
As a result of these biases, many have asked: Would a solution be to train a separate model just for this labeling task? Multiple models have been released with the goal of substituting for frontier models as a data labeling tool, such as critic models Shepherd [51] and CriticLLM [52] or models for evaluating response performance akin to Auto-J [53], Prometheus [54], Prometheus 2 [55], or Prometheus-Vision [56], but they are not widely adopted in documented training recipes. Some find scaling inference via repeated sampling [57] [58] [59], self-refinement [60], or tournament ranking [61] provides a better estimate of the true judgment or higher-quality preference pairs. Other calibration techniques co-evolve the generation and judgment capabilities of the model [62]. It is accepted that while biases exist, the leading language models are trained extensively for this task – as it’s needed for both internal operations at AI labs and is used extensively by customers – so it is generally not needed to train your own judge, unless your task involves substantial private information that is not exposed on the public internet.
Constitutional AI
The method of Constitutional AI (CAI), which Anthropic uses in their Claude models, is the earliest documented, large-scale use of synthetic data for RLHF training. Constitutional AI involves generating synthetic data in two ways:
- Critiques of instruction-tuned data to follow a set of principles like “Is the answer encouraging violence?” or “Is the answer truthful?” When the model generates answers to questions, it checks the answer against the list of principles in the constitution, refining the answer over time. Then, the model is fine-tuned on this resulting dataset.
- Generating pairwise preference data by using a language model to answer which completion was better, given the context of a random principle from the constitution (similar to research for principle-guided reward models [63]). Then, RLHF proceeds as normal with synthetic data, hence the RLAIF name.
Largely, CAI is known for the second half above, the preference data, but the methods introduced for instruction data are used in general data filtering and synthetic data generation methods across post-training.
CAI can be formalized as follows.
By employing a human-written set of principles, which they term a constitution, Bai et al. 2022 use a separate LLM to generate artificial preference and instruction data used for fine-tuning [48]. A constitution \(\mathcal{C}\) is a set of written principles indicating specific aspects to focus on during a critique phase. The instruction data is curated by repeatedly sampling a principle \(c_i \in \mathcal{C}\) and asking the model to revise its latest output \(y^i\) to the prompt \(x\) to align with \(c_i\). This yields a series of instruction variants \(\{y^0, y^1, \cdots, y^n\}\) from the principles \(\{c_{0}, c_{1}, \cdots, c_{n-1}\}\) used for critique. The final data point is the prompt \(x\) together with the final completion \(y^n\), for some \(n\).
The preference data is constructed in a similar, yet simpler way by using a subset of principles from \(\mathcal{C}\) as context for a feedback model. The feedback model is presented with a prompt \(x\), a set of principles \(\{c_0, \cdots, c_n\}\), and two completions \(y_0\) and \(y_1\) labeled as answers (A) and (B) from a previous RLHF dataset. The new data point is generated by having a language model select which output (A) or (B) is both higher quality and more aligned with the stated principle. In earlier models this could be done by prompting the model with The answer is:, and then looking at which token (A or B) had a higher probability, but now this is more commonly handled by a model that’ll explain its reasoning and then select an answer – commonly referred to as a type of generative reward model [64].
Further Reading on CAI
There are many related research directions and extensions of Constitutional AI, but few of them have been documented as clear improvements in RLHF and post-training recipes.
- OpenAI has released a Model Spec [65], which is a document stating the intended behavior for their models, and stated that they are exploring methods for alignment where the model references the document directly (which could be seen as a close peer to CAI). OpenAI has continued to update their spec and trained its reasoning models such as o1 with a method called Deliberative Alignment [66] to align the model while referencing these safety or behavior policies.
- Anthropic has continued to use CAI in their model training, updating the constitution Claude uses [67] and experimenting with how population collectives converge on principles for models and how that changes model behavior when external groups create principles on their own and then share them with Anthropic to train the models [68].
- The open-source community has explored replications of CAI applied to open datasets [69] and for explorations into creating dialogue data between LMs [70].
- Other work has used principle-driven preferences or feedback with different optimization methods. Sun et al. 2023 [71] use principles as context for the reward models, which were used to train the Dromedary models [63]. Glaese et al. 2022 [72] use principles to improve the accuracy of human judgments in the RLHF process. Liu et al. 2025 [73] train a reward model to generate its own principles at inference time, and use these to deliver a final score. Franken et al. 2024 [74] formulate principle-following as a mutual information maximization problem that the pretrained model can learn with no labels.
Rubrics: Prompt-Specific AI Feedback for Training
AI feedback’s role in training grew in late 2024 and into 2025 as the field looked for avenues to scale reinforcement learning with verifiable rewards (see Chapter 7). The idea of rubrics emerged as a way to get nearly-verifiable criteria for prompts that do not have clearly verifiable answers. This would allow a model to try to generate multiple answers to a problem and update (with RL) towards the best answers. This idea is closely related to other methods discussed in this chapter, and likely began functioning as the LLM judges and synthetic data practices improved across the industry. Now, RL with rubrics as rewards is established in providing meaningful improvements across skills such as scientific reasoning or factuality [75], [76], [77], [78].
An example rubric is shown below with its associated prompt [78]:
**Prompt**: As a museum curator, can you suggest five obscure artifacts that would be perfect for a "Mysteries of the Ancient World" exhibit? Each artifact should come from a different culture and time period, with a brief description of their historical significance and mysterious origins. These artifacts should leave visitors wondering about the secrets and lost knowledge of our past. Thank you for your expertise in bringing this exhibit to life.
** Rubric**:
1. The response includes exactly five distinct artifacts as requested. [Hard Rule]
2. The response ensures each artifact originates from a different culture and time period. [Hard Rule]
3. The response provides a brief description of each artifact's historical significance. [Hard Rule]
4. The response provides a brief description of each artifact's mysterious origins or unexplained aspects. [Hard Rule]
5. The response conveys a sense of intrigue and mystery that aligns with the theme of the exhibit. [Hard Rule]
6. The response clearly and accurately communicates information in a well-organized and coherent manner. [Principle]
7. The response demonstrates precision and clarity by avoiding unnecessary or irrelevant details. [Principle]
8. The response uses informative and engaging language that stimulates curiosity and critical thinking. [Principle]
9. The response shows thoughtful selection by ensuring each example contributes uniquely to the overall theme without redundancy. [Principle]
10. The response maintains consistency in style and format to enhance readability and comprehension. [Principle]The [Hard Rule] and [Principle] are specific tags to denote the priority of a certain piece of feedback. Other methods of indicating importance can be used, such as simple priority numbers.
Rubric generation is generally done per-prompt in the training data, which accumulates meaningful synthetic data costs in preparation. To alleviate this, a general rubric is often applied as a starting point per-domain, and then the fine-grained rubric scores per-prompt are assigned by a supervising language model to guide the feedback for training. An example prompt to generate a rubric for a science task is shown below [75]:
You are an expert rubric writer for science questions in the domains of Biology, Physics, and Chemistry.
Your job is to generate a self-contained set of evaluation criteria ("rubrics") for judging how good a response is to a given question in one of these domains.
Rubrics can cover aspects such as factual correctness, depth of reasoning, clarity, completeness, style, helpfulness, and common pitfalls.
Each rubric item must be fully self-contained so that non-expert readers need not consult
any external information.
Inputs:
- question: The full question text.
- reference_answer: The ideal answer, including any key facts or explanations.
Total items:
- Choose 7-20 rubric items based on question complexity.
Each rubric item must include exactly three keys:
1. title (2-4 words)
2. description: One sentence beginning with its category prefix, explicitly stating what to look for.
For example:
- Essential Criteria: States that in the described closed system, the total mechanical energy (kinetic plus potential)
before the event equals the total mechanical energy after the event.
- Important Criteria: Breaks down numerical energy values for each stage, demonstrating that initial kinetic
energy plus initial potential energy equals final kinetic energy plus final potential energy.
- Optional Criteria: Provides a concrete example, such as a pendulum converting between kinetic and potential
energy, to illustrate how energy shifts within the system.
- Pitfall Criteria: Does not mention that frictional or air-resistance losses are assumed negligible when applying
conservation of mechanical energy.
3. weight: For Essential/Important/Optional, use 1-5 (5 = most important); for Pitfall, use -1 or -2.
Category guidance:
- Essential: Critical facts or safety checks; omission invalidates the response.
- Important: Key reasoning or completeness; strongly affects quality.
- Optional: Nice-to-have style or extra depth.
- Pitfall: Common mistakes or omissions; highlight things often missed.
Format notes:
- When referring to answer choices, explicitly say "Identifies (A)", "Identifies (B)", etc.
- If a clear conclusion is required (e.g. "The final answer is (B)"), include an Essential Criteria for it.
- If reasoning should precede the final answer, include an Important Criteria to that effect.
- If brevity is valued, include an Optional Criteria about conciseness.
Output: Provide a JSON array of rubric objects. Each object must contain exactly three keys-title, description, and weight.
Do not copy large blocks of the question or reference_answer into the text. Each description must begin with its category
prefix, and no extra keys are allowed.
Now, given the question and reference_answer, generate the rubric as described.
The reference answer is an ideal response but not necessarily exhaustive; use it only as guidance.Another, simpler example follows as [77]:
SYSTEM:
You generate evaluation rubrics for grading an assistant's response to a user prompt.
Rubric design rules:
- Each criterion must be atomic (one thing), objective as possible, and written so a grader can apply it consistently.
- Avoid redundant/overlapping criteria; prefer criteria that partition different failure modes.
- Make criteria self-contained (don't rely on unstated context).
- Include an importance weight for each criterion.
Output format (JSON only):
{
"initial_reasoning": "<brief rationale for what matters for this prompt>",
"rubrics": [
{
"reasoning": "<why this criterion matters>",
"criterion": "<clear, testable criterion>",
"weight": <integer 1-10>
},
...
]
}
USER:
User prompt:
{prompt}
Generate the rubric JSON now.As you can see, the prompts can be very detailed and are tuned to the training setup.
Rubrics with RL training are going to continue to evolve beyond their early applications to instruction following [79], deep research [80], evaluating deep research agents [81], or long-form generation [82].