What is a language model?
Core properties:
- A language model assigns probabilities to text.
- Chunks of words are broken down as tokens, which are the internal representation of the model.
- Given previous tokens, it predicts the next token. Repeating this produces a completion one step at a time (this is called autoregressive).
What is a (modern) language model?
Modern language models:
- Have billions to trillions of parameters.
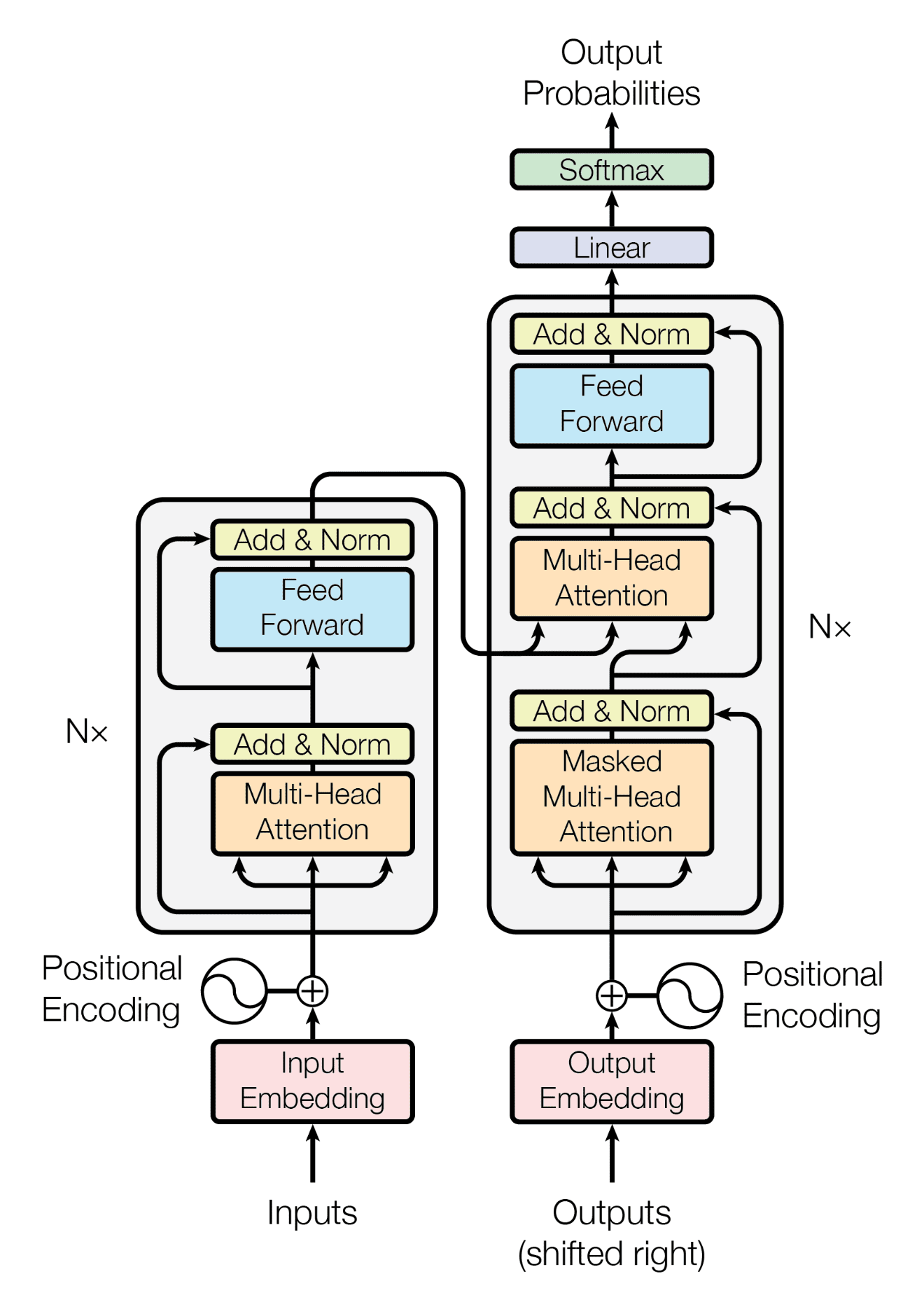
- Largely downstream of the Transformer architecture, which popularized the use of the self-attention mechanism along with fully-dense layers.
- Predict and work over much more than text: Gemini and ChatGPT work with images, audio, and video.
2017: The Transformer is born
- 2017: the Transformer is born
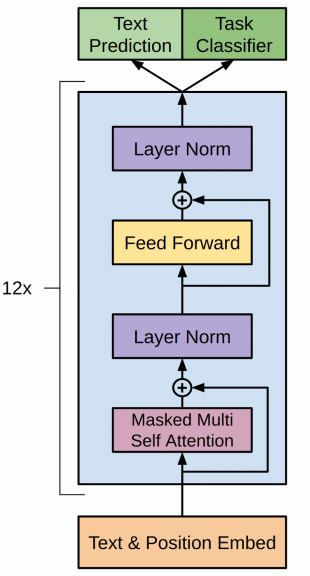
2018: GPT-1, ELMo, and BERT
- 2017: the Transformer is born
- 2018: GPT-1, ELMo, and BERT released
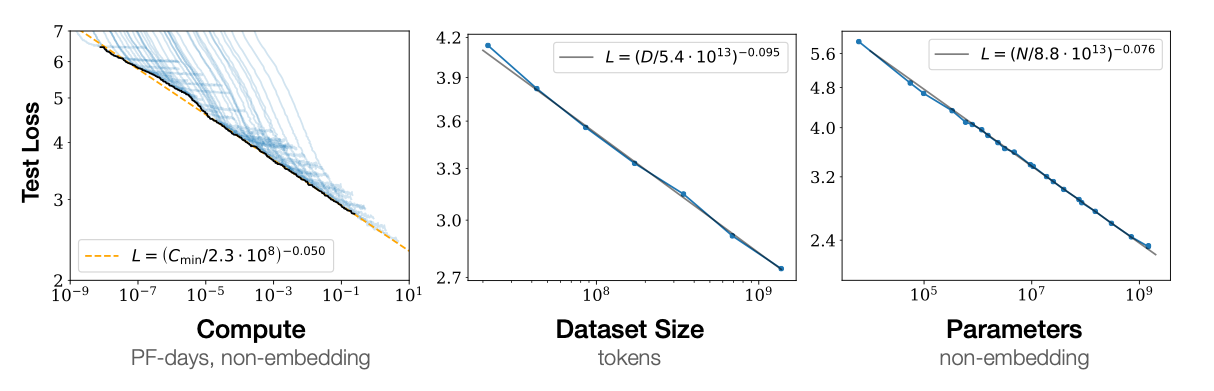
2019: GPT-2 and scaling laws
- 2017: the Transformer is born
- 2018: GPT-1, ELMo, and BERT released
- 2019: GPT-2 and scaling laws
2020: GPT-3 surprising capabilities
- 2017: the Transformer is born
- 2018: GPT-1, ELMo, and BERT released
- 2019: GPT-2 and scaling laws
- 2020: GPT-3 surprising capabilities
2021: Stochastic Parrots
- 2017: the Transformer is born
- 2018: GPT-1, ELMo, and BERT released
- 2019: GPT-2 and scaling laws
- 2020: GPT-3 surprising capabilities
- 2021: Stochastic Parrots

2022: ChatGPT
- 2017: the Transformer is born
- 2018: GPT-1, ELMo, and BERT released
- 2019: GPT-2 and scaling laws
- 2020: GPT-3 surprising capabilities
- 2021: Stochastic Parrots
- 2022: ChatGPT
2023: GPT-4 and frontier-scale
- 2017: the Transformer is born
- 2018: GPT-1, ELMo, and BERT released
- 2019: GPT-2 and scaling laws
- 2020: GPT-3 surprising capabilities
- 2021: Stochastic Parrots
- 2022: ChatGPT
- 2023: GPT-4 and frontier-scale
2024: o1 and reasoning models
- 2017: the Transformer is born
- 2018: GPT-1, ELMo, and BERT released
- 2019: GPT-2 and scaling laws
- 2020: GPT-3 surprising capabilities
- 2021: Stochastic Parrots
- 2022: ChatGPT
- 2023: GPT-4 and frontier-scale
- 2024: o1 and reasoning models
2025: o3, Claude Code, and agents
- 2017: the Transformer is born
- 2018: GPT-1, ELMo, and BERT released
- 2019: GPT-2 and scaling laws
- 2020: GPT-3 surprising capabilities
- 2021: Stochastic Parrots
- 2022: ChatGPT
- 2023: GPT-4 and frontier-scale
- 2024: o1 and reasoning models
- 2025: o3, Claude Code, and agents
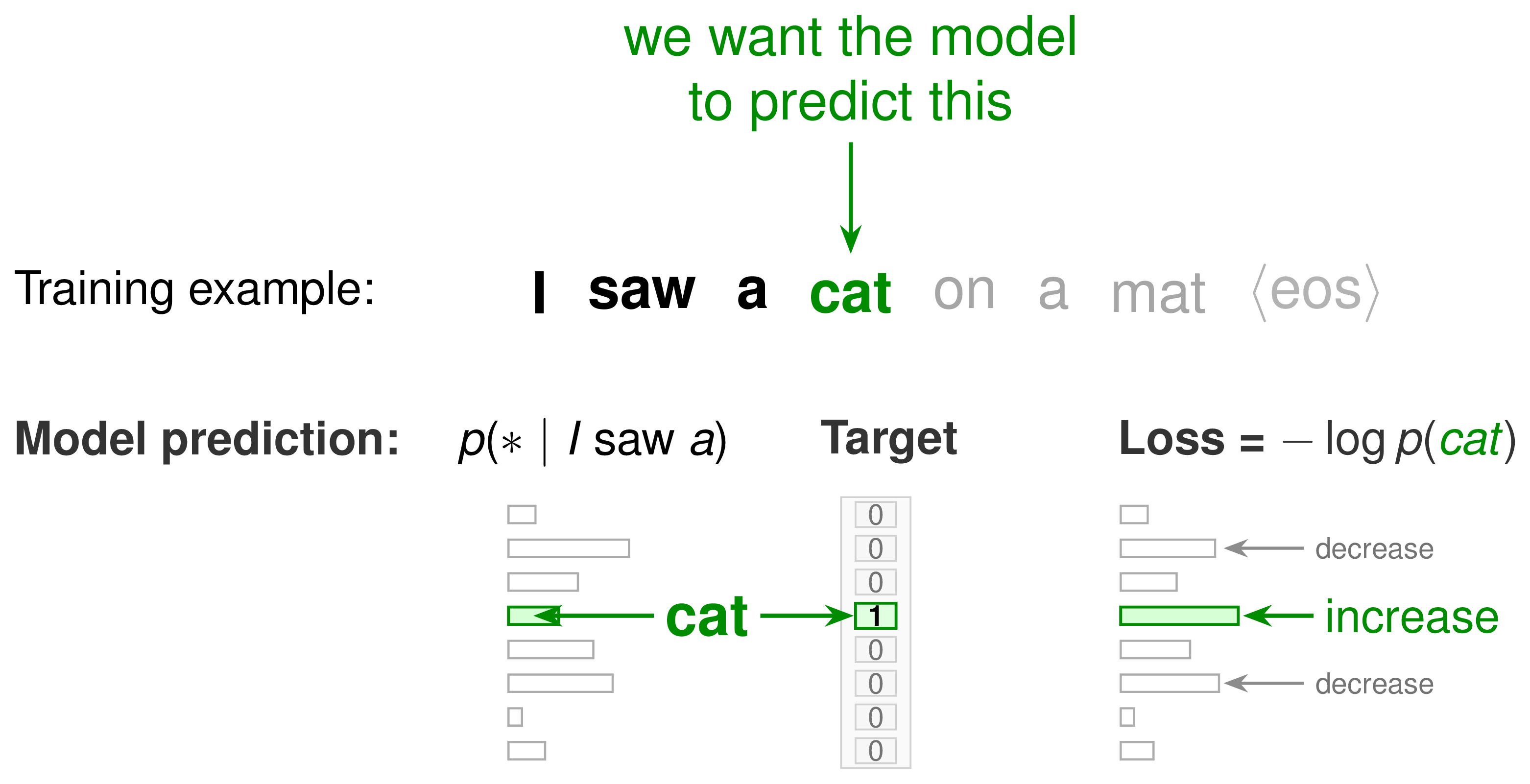
Pretraining: next-token prediction
- Train on trillions of tokens of text from the web, books, code, and documents
- Models are often trained on 5-50+ trillion tokens
- 1T of text tokens is about 3-5 TB of data
- Labs gather and filter 10-20X more data than is used for the model
- Total data funnel targeted for models is on the order of petabytes
- Objective: predict the next token in each sequence
- Result: Incredible, flexible, useful models
Which is the better backflip?


RLHF before language models
- TAMER (Knox & Stone, 2008) — humans score agent actions to learn a reward
- Christiano et al. 2017 — RLHF on Atari trajectory preferences
- Ziegler et al. 2019 — first RLHF on language models
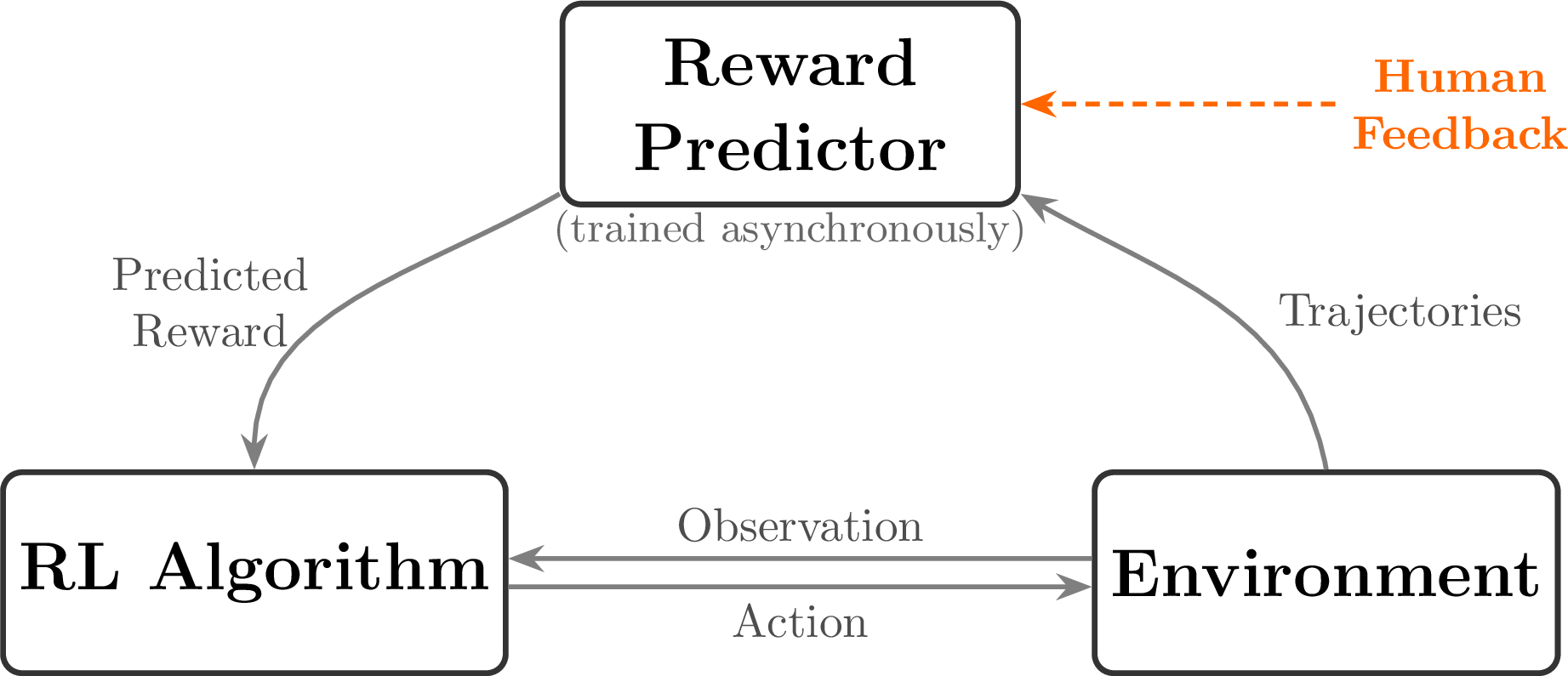
Left: Human feedback; Right: Hand-designed reward function
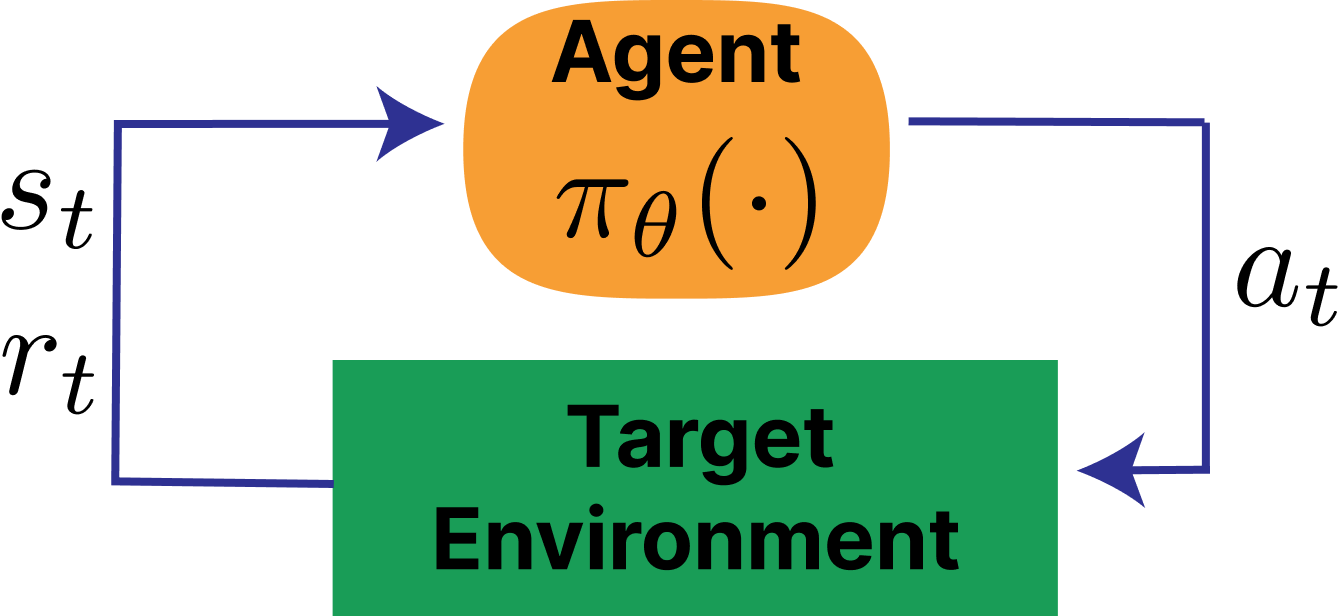
Classical RL
A reinforcement learning problem is often written as a Markov Decision Process (MDP):
- state space \mathcal{S}, action space \mathcal{A}
- transition dynamics P(s_{t+1}\mid s_t, a_t)
- reward function r(s_t, a_t) and discount \gamma
- optimize cumulative return over a trajectory
Classical RL vs. RLHF
Classical RL
- Agent takes actions a_t in an environment with states s_t
- Reward is a known function r(s_t, a_t) from the environment per step
- Optimize cumulative return over a trajectory (total steps T)
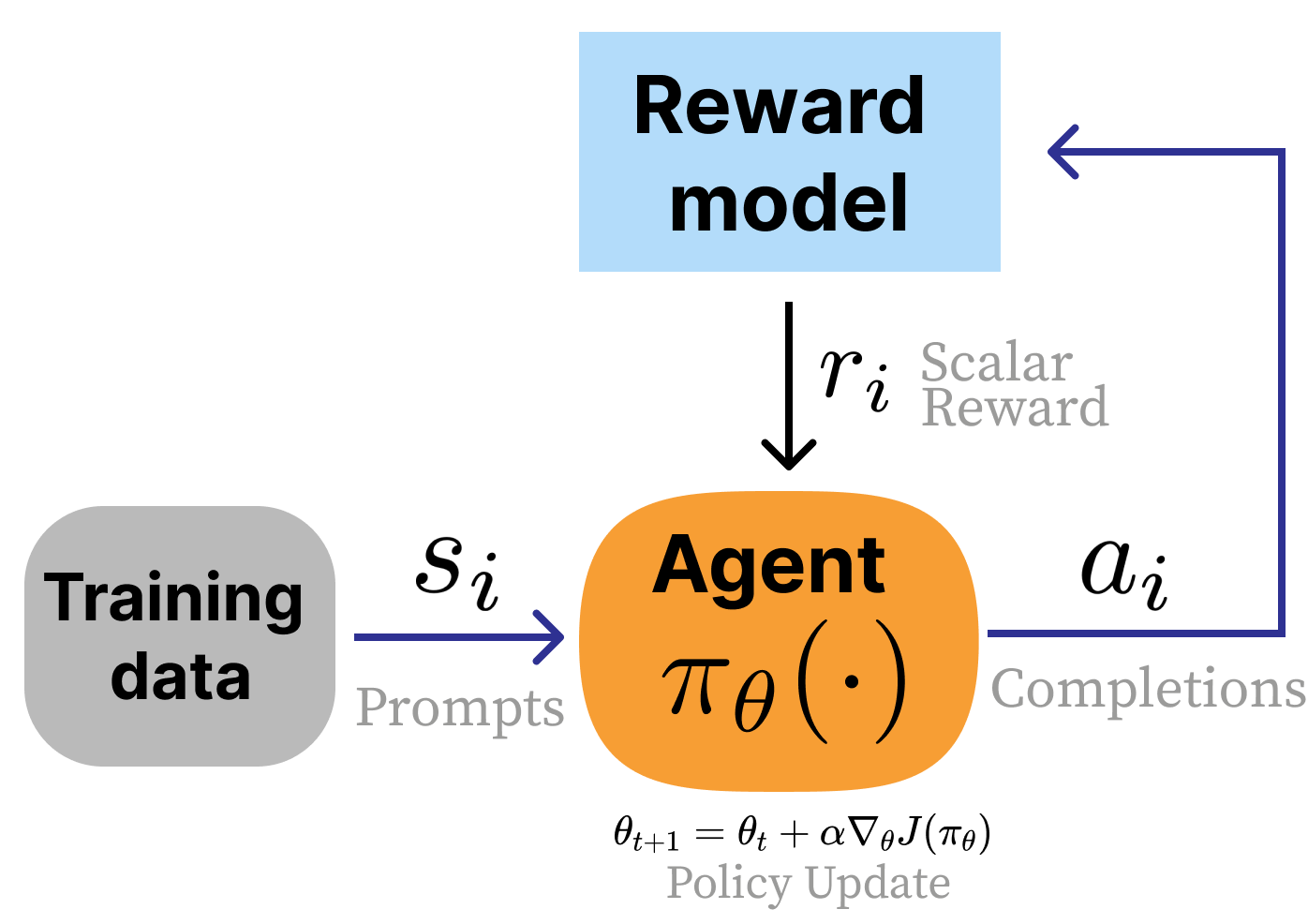
RLHF
- No environment — prompts sampled from a dataset
- Reward is learned from human preferences (a proxy)
- Response-level reward (bandit-style, not per-token)
- Regularized with KL penalty to stay close to the base model
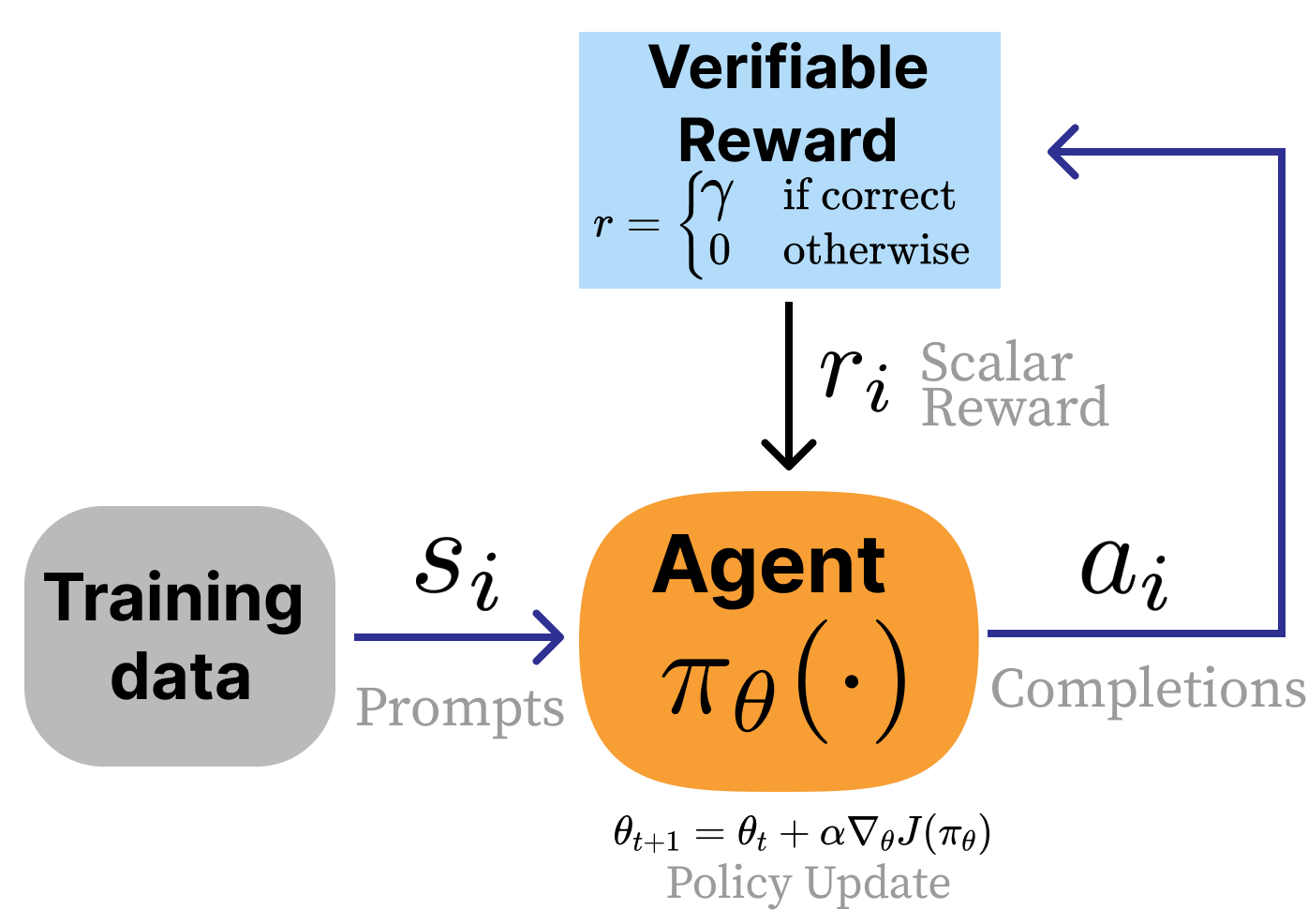
Reinforcement learning with Verifiable rewards
Apply the same RL algorithms to LLMs when the answer can be checked directly. No need to train a reward model:
- E.g. Math: check the final answer.
Code: run the tests. - No learned reward model — no proxy objective
- Enables scaling RL compute on reasoning tasks
- Unlocked inference time scaling: Spending more compute at generation time per problem increases performance log-linearly w.r.t. compute
- RLVR was named by Tülu 3 (Lambert et al., 2024) and popularized by DeepSeek R1 (Guo et al., 2025)
The path to modern RLHF
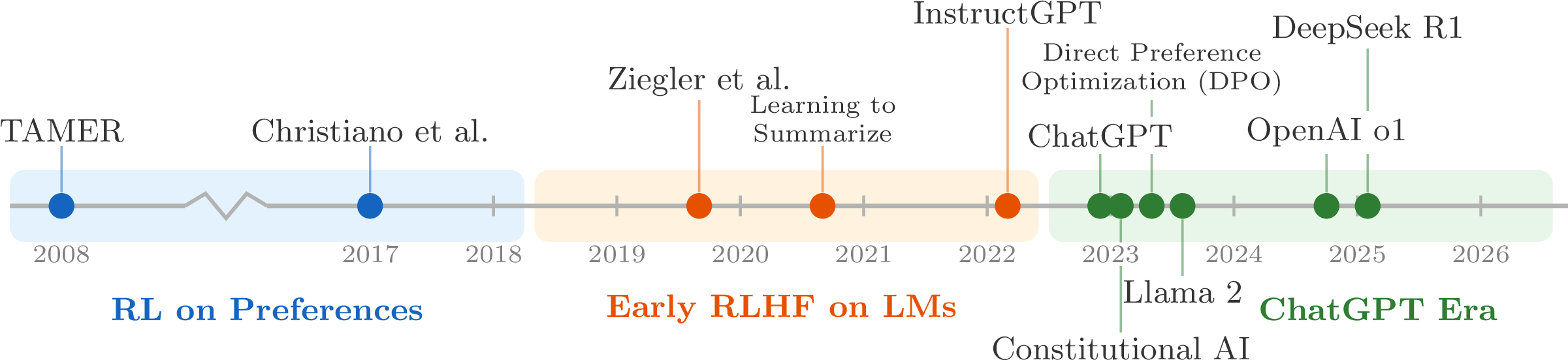
- Ziegler 2019 (Ziegler et al., 2019) — first RLHF on language models
- InstructGPT (Ouyang et al., 2022) — the canonical RLHF recipe behind ChatGPT
- Constitutional AI (Bai et al., 2022) — Introduced early methods for AI feedback in Claude
- DPO (Rafailov et al., 2023) — direct preference optimization (DPO) without a reward model
- Llama 3 (Grattafiori et al., 2024) and Tülu 3 (Lambert et al., 2024) — modern multi-stage recipes
- DeepSeek R1 (Guo et al., 2025) — popularized RLVR
InstructGPT’s 3-step RLHF recipe
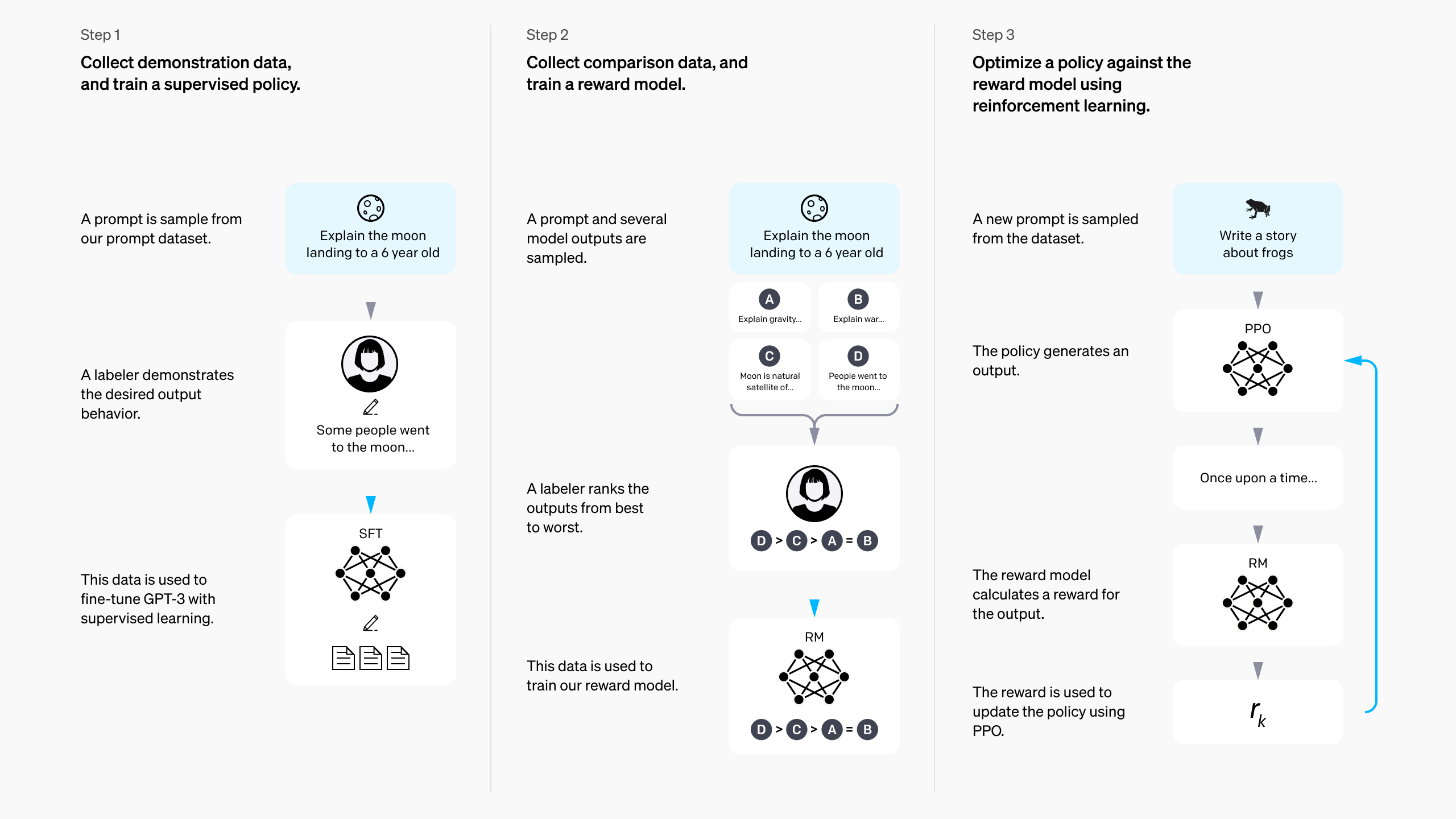
Step 3/3: RL against the reward model
Where everything comes together (and RLHF gets its name):
- Sample a batch of prompts x_i from the dataset \mathcal{D}
- Generate completions y_i \sim \pi_\theta(\cdot \mid x_i) from the model being trained
- Score them with the reward model r_\phi(x_i, y_i)
- Add a KL penalty so the policy stays close to the SFT/reference model.1
- Update the policy with a policy-gradient RL algorithm (Proximal Policy Optimization, PPO in InstructGPT & ChatGPT)
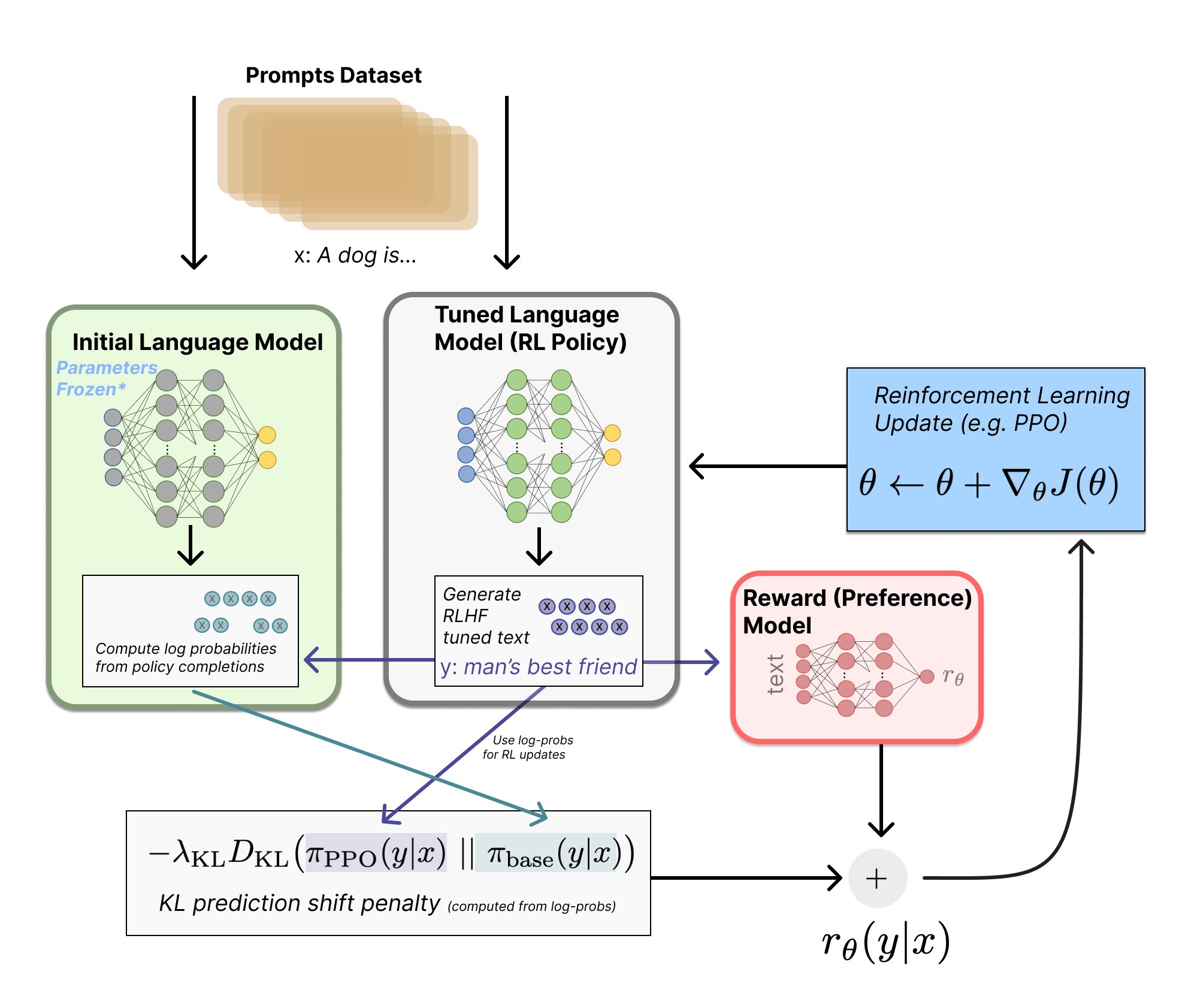
The early days: InstructGPT

Early on, RLHF had a well-documented, simple enough approach.
- InstructGPT made the classic three-stage recipe canonical: SFT, reward modeling, then RL against the reward model. OpenAI even hinted that the original ChatGPT used this!
- This became the intellectual template for much of modern post-training.
From RLHF to post-training
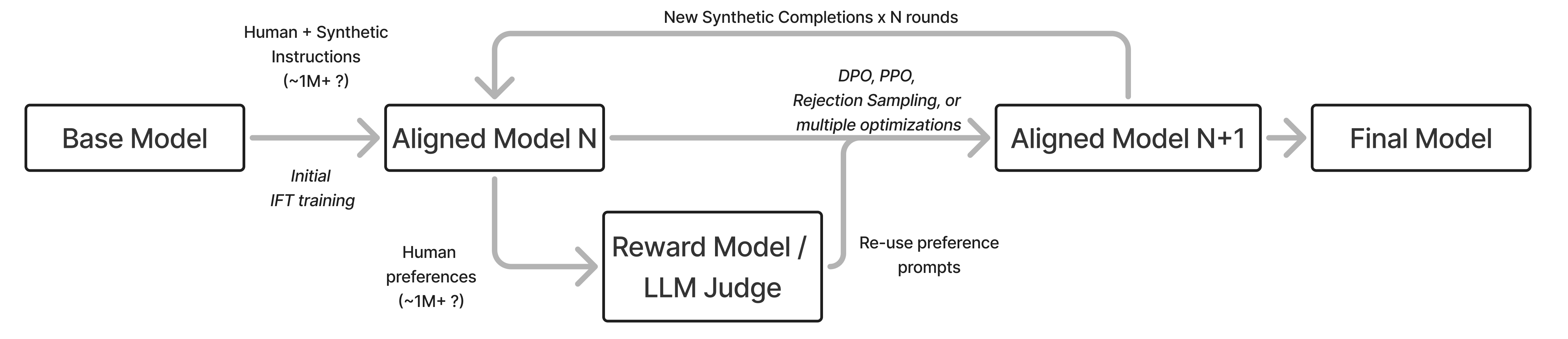
What began as an “RLHF” recipe evolved into a complex series of steps to get the final, best model (e.g. Nemotron 4 340B, Llama 3.1).
- Modern systems keep the same core idea of using multiple optimizers with different strengths and weaknesses, but add more stages, more data, and more filtering.
- This trend has only continued, and recipes ebb and flow, as tools like RLVR and model merging change the scope of what is doable in different ways.
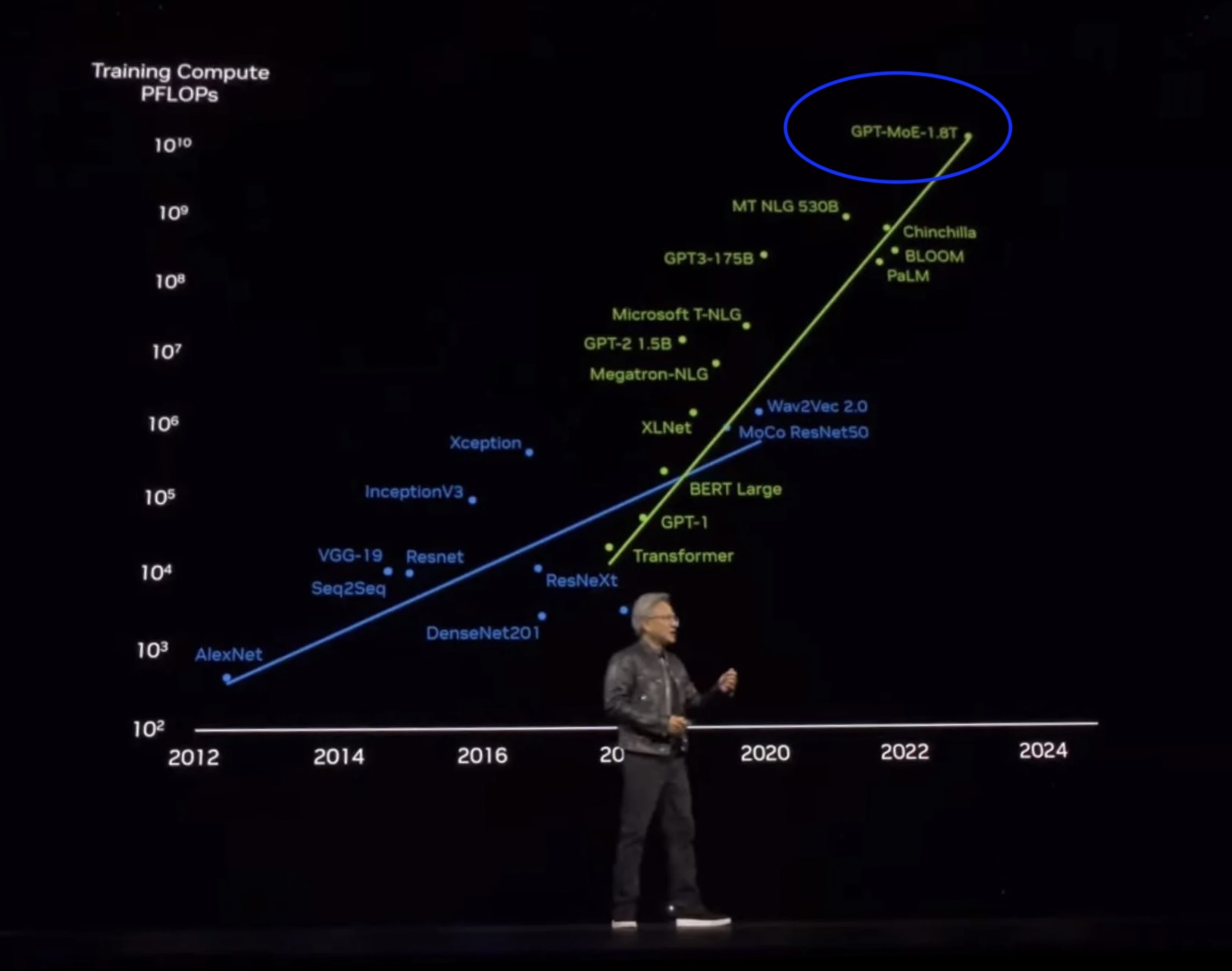
OpenAI’s seminal scaling plot with o1-preview
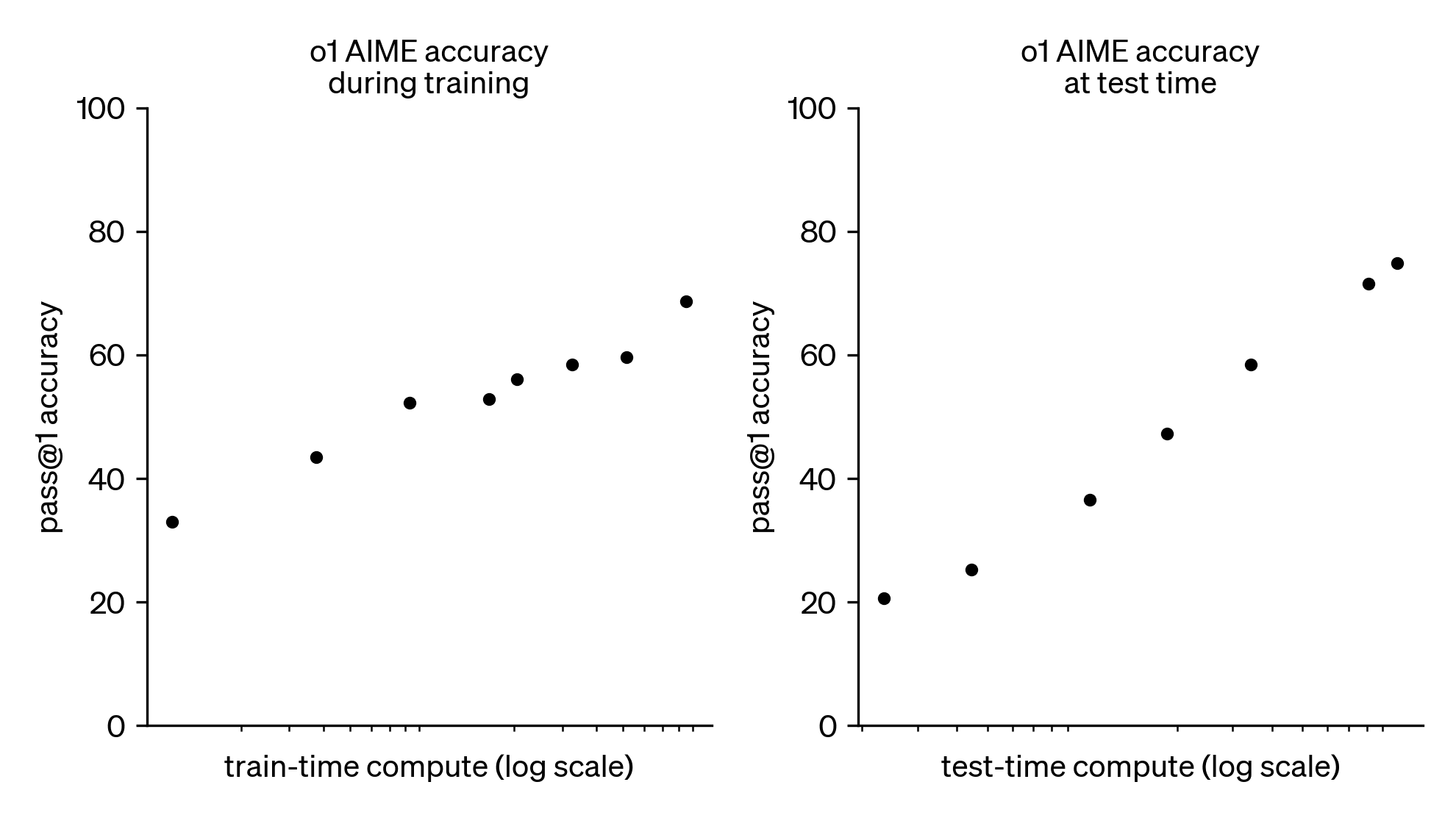
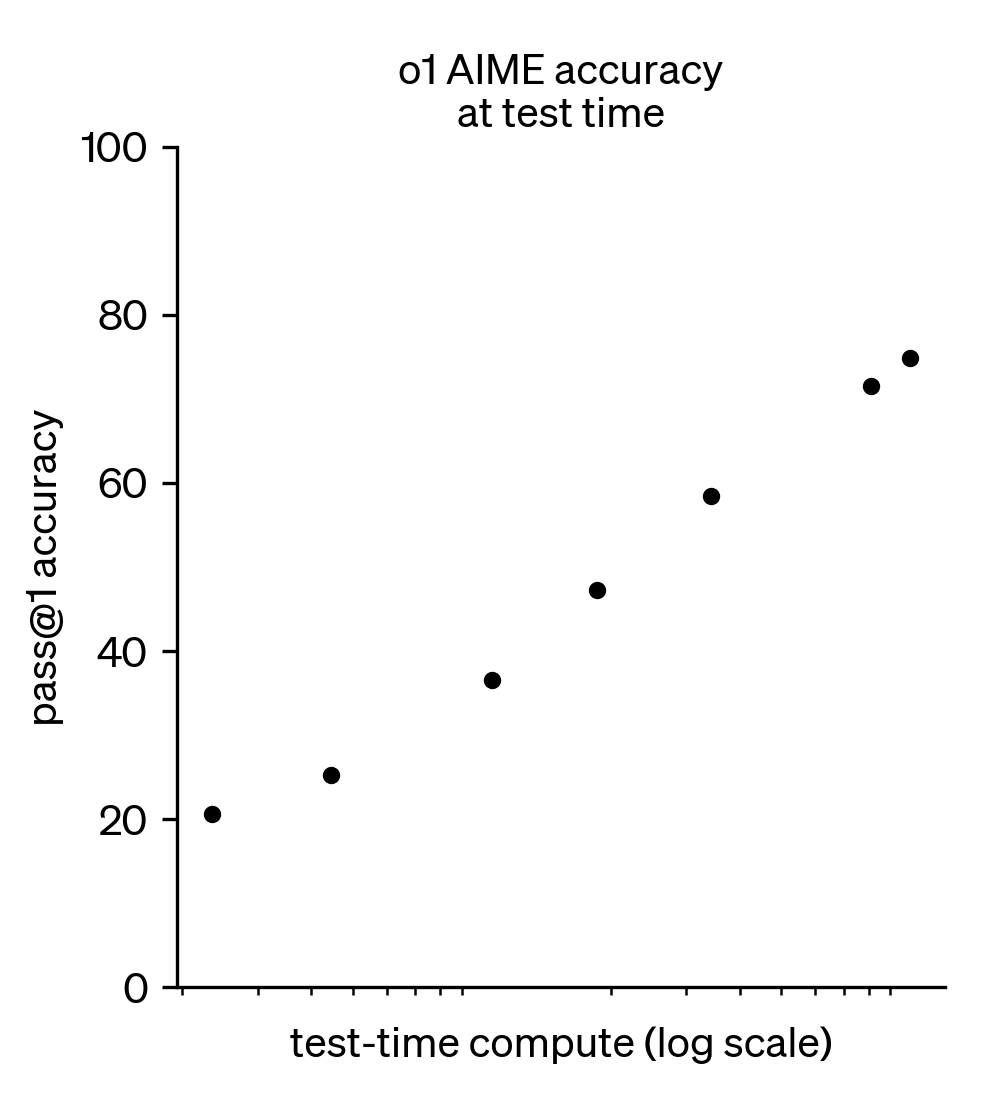
o1: Test-time scaling
A log-linear relationship between inference compute (number of tokens generated) and downstream performance.
- This is a fundamental property of models, unlocked in its popular form with RLVR
- Can be done in many ways: One long chain of thought (CoT) sequence, multiple agents in parallel, or mixes of the two
- Improving inference-time scaling changes the slope and offset of the curve
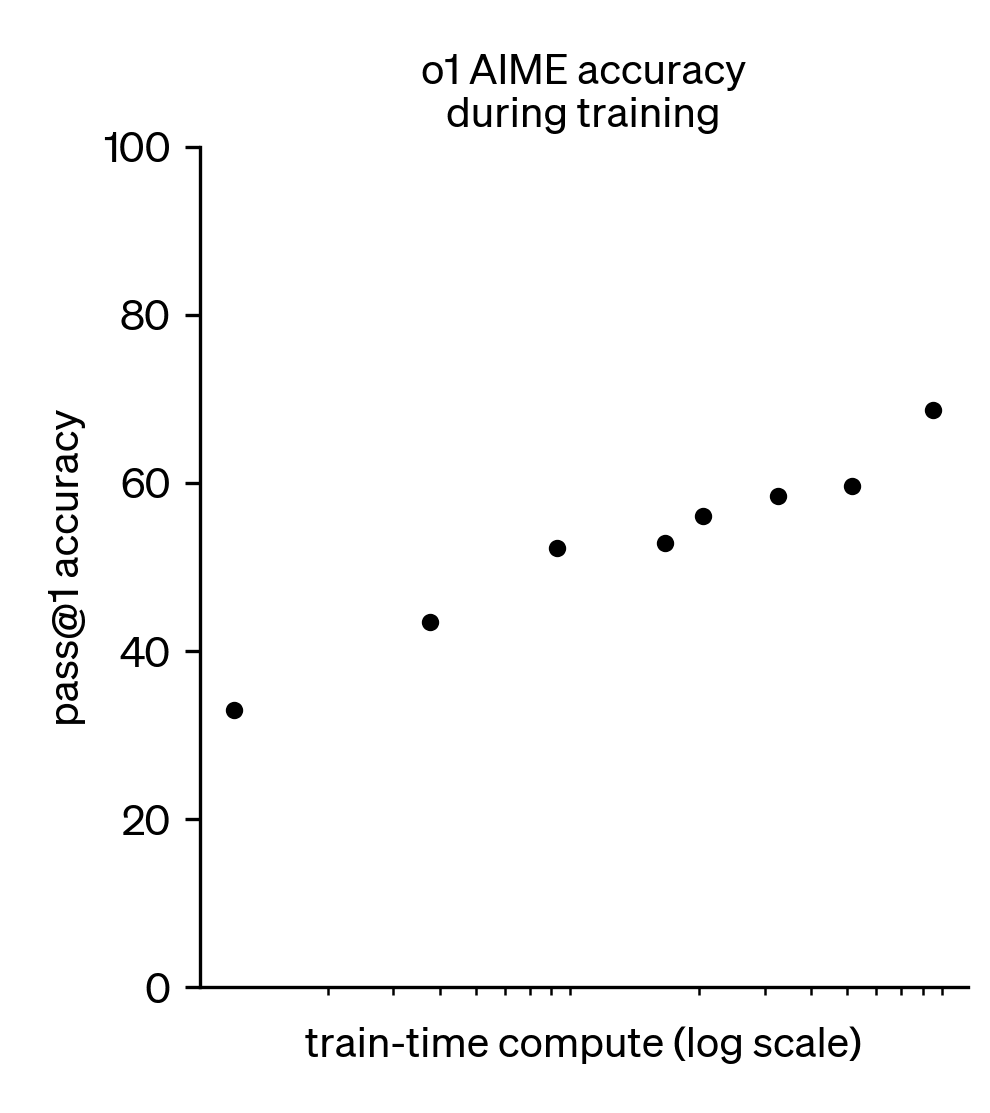
o1: Training-time scaling (with reinforcement learning!)
An often underplayed portion of the o1 release (and future reasoning/agentic models).
- Scaling reinforcement learning compute also has a log-linear return on performance!
- The core question: Is scaling RL training just eliciting more from the base model or actually teaching new abilities?
Results in a two-sided scaling landscape for training language models – both pretraining and post-training. The third place of scaling is at inference (no weight updates there).
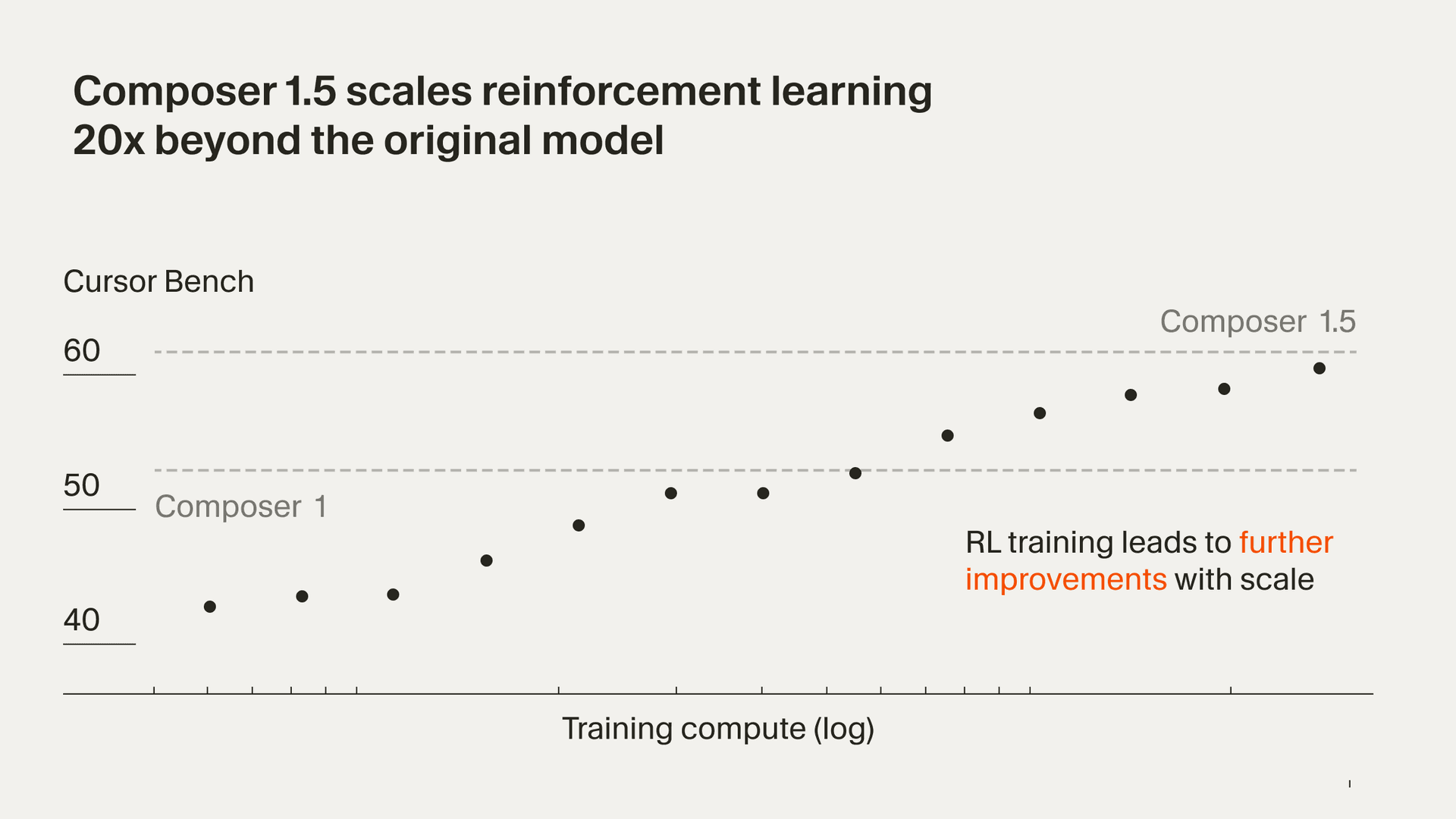
Cursor Composer 1.5: RL scaling
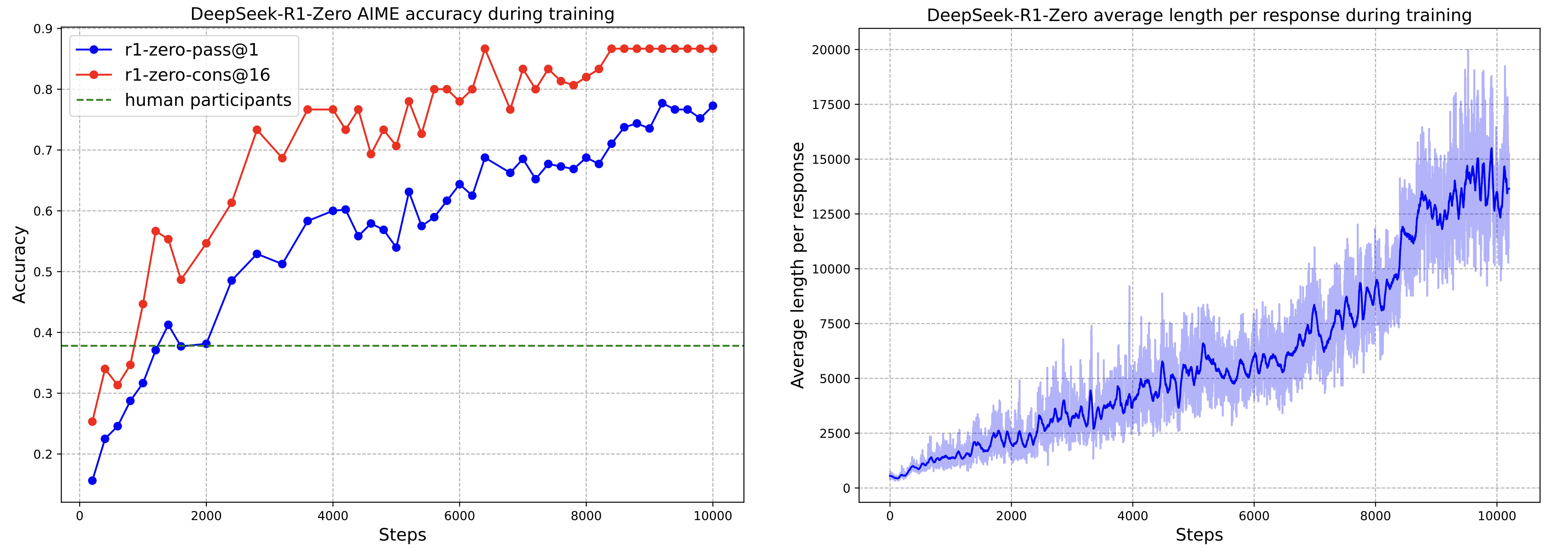
DeepSeek-R1-Zero: RL scaling
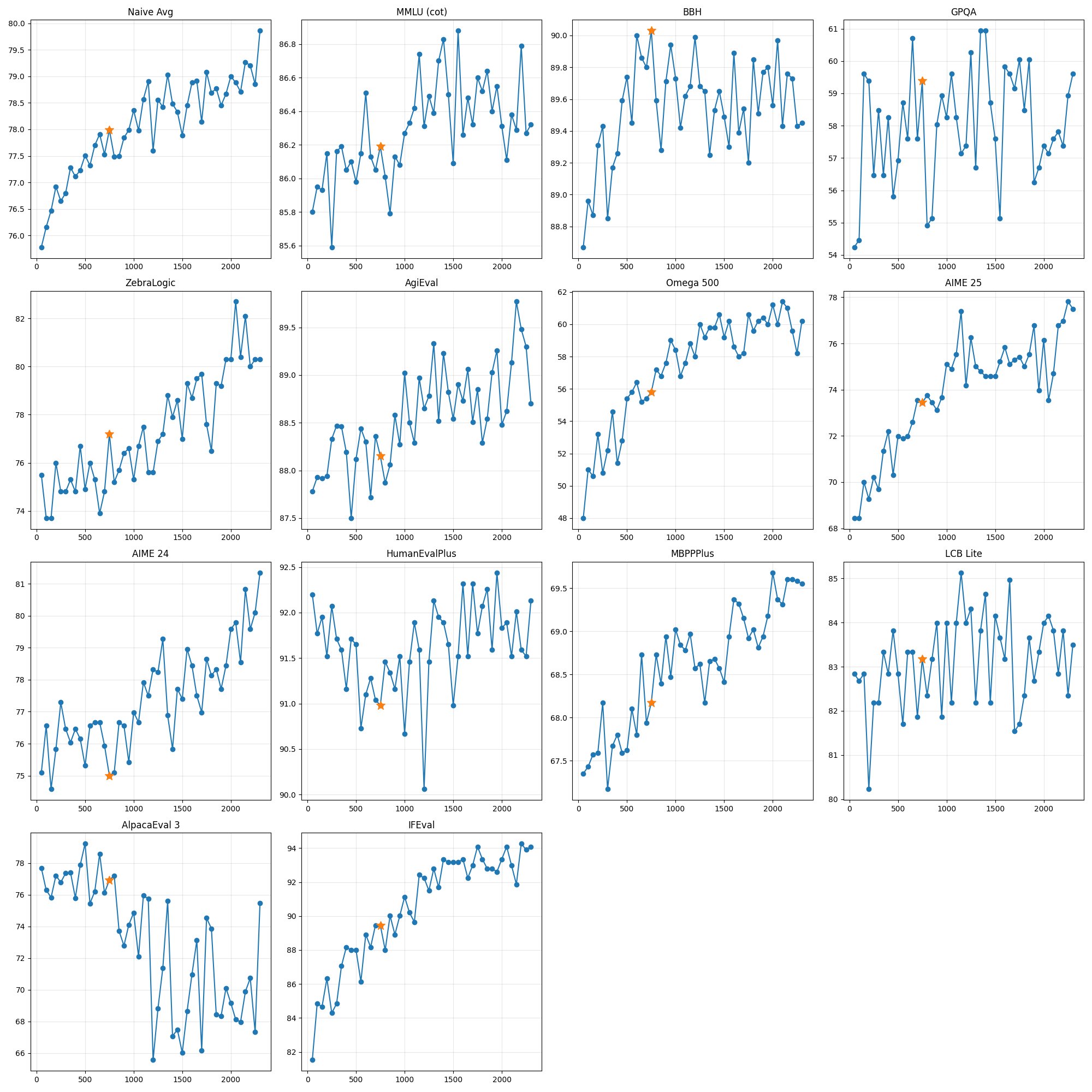
Olmo 3.1: extending the RL run
One of the few “fully open” large-scale RL runs to date.
- Training a general, 32B reasoning model.
- Full RL training took about 28 days on 224 GPUs.
- Improvements in performance were very consistent across the run, in fact they were still going up when we had to stop it!