Rejection Sampling
Rejection Sampling (RS) is one of the most widely used yet least documented methods in preference fine-tuning. Many prominent RLHF papers use it as a core component of their training pipeline, yet no canonical implementation or explanation of why it works so well exists. RS can be applied at multiple points in the training pipeline – after instruction fine-tuning, after RL-based optimization, or even after RLVR – making it a versatile but hard-to-place tool. Combined with its underdocumented nature, this is why it appears here at the end of the core optimization methods.
Rejection sampling operates by curating new candidate completions, filtering them based on a trained reward model, and then fine-tuning the original model only on the top completions (the same loss function as instruction tuning).
The name originates from computational statistics [1], where one wishes to sample from a complex distribution, but does not have a direct method to do so. To alleviate this, one samples from a distribution that is simpler to model and uses a heuristic to check if the sample is permissible. With language models, the target distribution is high-quality completions to prompts, the filter is a reward model, and the sampling distribution is the current model.
WebGPT [2], Anthropic’s Helpful and Harmless agent [3], OpenAI’s popular paper on process reward models [4], Llama 2 Chat models [5], and other seminal works all use this baseline; more recent work has formalized it directly (e.g., RAFT [6] for applying it to alignment in multiple modalities and Statistical Rejection Sampling Optimization (RSO) [7] that gives a principled overview of how rejection sampling relates to other preference learning objectives).
Throughout this chapter, we use \(x\) to denote prompts and \(y\) to denote completions. This notation is common in the language model literature, where methods operate on full prompt-completion pairs rather than individual tokens.
Training Process, Step by Step
Rejection sampling overall follows a few stages.
- Prompt and reward model selection: First, you must select the prompts you want to train on, relative to other stages of training. The simplest method is to re-use every prompt from the first SFT/IFT stage, but this can cause some overfitting. Before doing rejection sampling, you must also have trained a reward model (see Chapter 5 for more information).
- Generate completions from the starting checkpoint: Next, one must generate completions to the selected prompts with the model they want to optimize. This can involve tweaking many settings, such as sampling temperature, top-p, max sequence length, number of completions per prompt, etc.
- Select top completions with a reward model: All completions are ranked by a reward model. This stage may also include deduplication to keep only one completion per prompt, though many such design choices come down to empirical ablation studies.
- SFT on top completions: To finish rejection sampling, one instruction fine-tunes the starting checkpoint on the selected completions.
A visual overview of the rejection sampling process is included below in fig. 1.
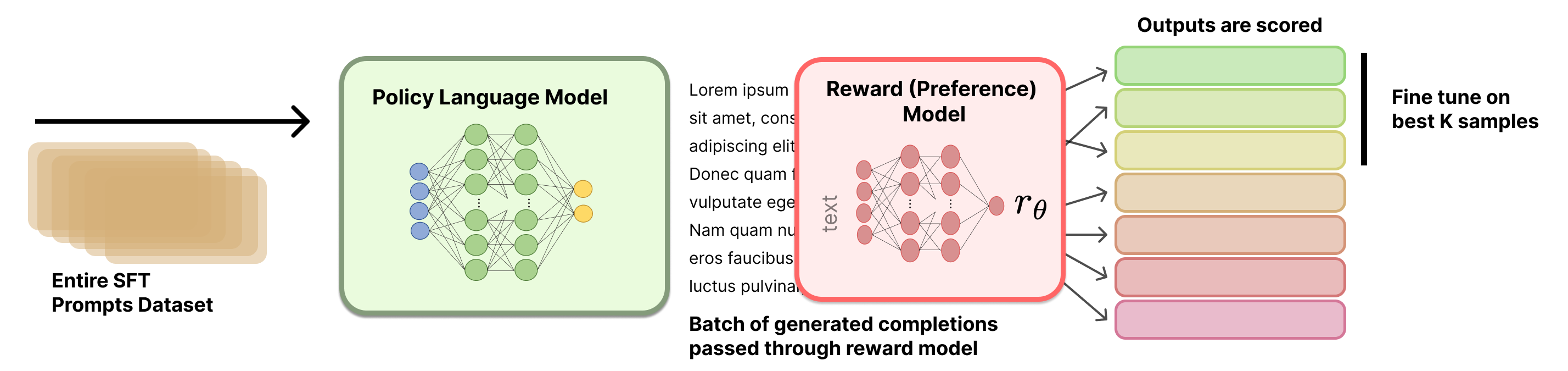
The actual details on which prompts to use, how to select a reward model, how to sequence rejection sampling, etc. are not well documented in the literature. This chapter provides an overview of the methods and leaves further experimentation to the reader.
Generating Completions
To generate a set of multiple candidate completions per prompt, let’s define a set of \(M\) prompts as a vector:
\[X = [x_1, x_2, ..., x_M]\qquad{(1)}\]
These prompts can come from many sources, but most commonly they come from the instruction training set.
For each prompt \(x_i\), we generate \(N\) completions. We can represent this as a matrix:
\[Y = \begin{bmatrix} y_{1,1} & y_{1,2} & \cdots & y_{1,N} \\ y_{2,1} & y_{2,2} & \cdots & y_{2,N} \\ \vdots & \vdots & \ddots & \vdots \\ y_{M,1} & y_{M,2} & \cdots & y_{M,N} \end{bmatrix}\qquad{(2)}\]
where \(y_{i,j}\) represents the \(j\)-th completion for the \(i\)-th prompt. Each row \(i\) corresponds to a single prompt \(x_i\) and contains its \(N\) candidate completions; each column \(j\) corresponds to the \(j\)-th sampled completion across all prompts.
Scoring Completions
Now, we pass all of these prompt-completion pairs through a reward model, to get a matrix of rewards. We’ll represent the rewards as a matrix \(R\):
\[R = \begin{bmatrix} r_{1,1} & r_{1,2} & \cdots & r_{1,N} \\ r_{2,1} & r_{2,2} & \cdots & r_{2,N} \\ \vdots & \vdots & \ddots & \vdots \\ r_{M,1} & r_{M,2} & \cdots & r_{M,N} \end{bmatrix}\qquad{(3)}\]
Each reward \(r_{i,j}\) is computed by passing the completion \(y_{i,j}\) and its corresponding prompt \(x_i\) through a reward model \(\mathcal{R}\):
\[r_{i,j} = \mathcal{R}(y_{i,j} \mid x_i)\qquad{(4)}\]
There are multiple methods to select the top completions to train on.
To formalize the process of selecting the best completions based on our reward matrix, we can define a selection function \(S\) that operates on the reward matrix \(R\).
Top Per Prompt
The first potential selection function takes the max reward per prompt.
\[S(R) = \left[\arg\max_{j} r_{1,j}, \arg\max_{j} r_{2,j}, ..., \arg\max_{j} r_{M,j}\right]\qquad{(5)}\]
This function \(S\) returns a vector of indices, where each index corresponds to the column with the maximum reward for each row in \(R\). We can then use these indices to select our chosen completions:
\[Y_{chosen} = [y_{1,S(R)_1}, y_{2,S(R)_2}, ..., y_{M,S(R)_M}]\qquad{(6)}\]
Top Overall Pairs
Alternatively, we can select the top \(K\) prompt-completion pairs from the entire set. First, let’s flatten our reward matrix \(R\) into a single vector:
\[R_{flat} = [r_{1,1}, r_{1,2}, ..., r_{1,N}, r_{2,1}, r_{2,2}, ..., r_{2,N}, ..., r_{M,1}, r_{M,2}, ..., r_{M,N}]\qquad{(7)}\]
This \(R_{flat}\) vector has length \(M \times N\), where \(M\) is the number of prompts and \(N\) is the number of completions per prompt.
Now, we can define a selection function \(S_K\) that selects the indices of the K highest values in \(R_{flat}\):
\[S_K(R_{flat}) = \text{argsort}(R_{flat})[-K:]\qquad{(8)}\]
where \(\text{argsort}\) returns the indices that would sort the array in ascending order, and we take the last \(K\) indices to get the \(K\) highest values.
To get our selected completions, we need to map these flattened indices back to our original completion matrix \(Y\). To recover the corresponding prompt-completion pair, you can map a zero-indexed flattened index \(k\) to \((i,j)\) via \(i = \lfloor k / N \rfloor + 1\) and \(j = (k \bmod N) + 1\).
Selection Example
Consider the case where we have the following situation, with five prompts and four completions. We will show two ways of selecting the completions based on reward.
\[R = \begin{bmatrix} 0.7 & 0.3 & 0.5 & 0.2 \\ 0.4 & 0.8 & 0.6 & 0.5 \\ 0.9 & 0.3 & 0.4 & 0.7 \\ 0.2 & 0.5 & 0.8 & 0.6 \\ 0.5 & 0.4 & 0.3 & 0.6 \end{bmatrix}\qquad{(9)}\]
First, per prompt. Intuitively, we can highlight the reward matrix as follows:
\[R = \begin{bmatrix} \textbf{0.7} & 0.3 & 0.5 & 0.2 \\ 0.4 & \textbf{0.8} & 0.6 & 0.5 \\ \textbf{0.9} & 0.3 & 0.4 & 0.7 \\ 0.2 & 0.5 & \textbf{0.8} & 0.6 \\ 0.5 & 0.4 & 0.3 & \textbf{0.6} \end{bmatrix}\qquad{(10)}\]
Using the argmax method, we select the best completion for each prompt:
\[S(R) = \left[\arg\max_{j} r_{i,j} \text{ for } i \in [1,5]\right]\qquad{(11)}\]
\[S(R) = [1, 2, 1, 3, 4]\qquad{(12)}\]
This means we would select:
- For prompt 1: completion 1 (reward 0.7)
- For prompt 2: completion 2 (reward 0.8)
- For prompt 3: completion 1 (reward 0.9)
- For prompt 4: completion 3 (reward 0.8)
- For prompt 5: completion 4 (reward 0.6)
Now, best overall. Let’s highlight the top five overall completion pairs.
\[R = \begin{bmatrix} \textbf{0.7} & 0.3 & 0.5 & 0.2 \\ 0.4 & \textbf{0.8} & 0.6 & 0.5 \\ \textbf{0.9} & 0.3 & 0.4 & \textbf{0.7} \\ 0.2 & 0.5 & \textbf{0.8} & 0.6 \\ 0.5 & 0.4 & 0.3 & 0.6 \end{bmatrix}\qquad{(13)}\]
First, we flatten the reward matrix:
\[R_{flat} = [0.7, 0.3, 0.5, 0.2, 0.4, 0.8, 0.6, 0.5, 0.9, 0.3, 0.4, 0.7, 0.2, 0.5, 0.8, 0.6, 0.5, 0.4, 0.3, 0.6]\qquad{(14)}\]
Now, we select the indices of the five highest values: \[S_5(R_{flat}) = [8, 5, 14, 0, 11]\qquad{(15)}\]
Mapping these back to our original matrix:
- Index 8 → prompt 3, completion 1 (reward 0.9)
- Index 5 → prompt 2, completion 2 (reward 0.8)
- Index 14 → prompt 4, completion 3 (reward 0.8)
- Index 0 → prompt 1, completion 1 (reward 0.7)
- Index 11 → prompt 3, completion 4 (reward 0.7)
Implementation Example
Here is a code snippet showing how the selection methods could be implemented.
import numpy as np
x = np.random.randint(10, size=10)
print(f"{x=}")
sorted_indices = np.argsort(x)
x_sorted = x[sorted_indices]
print(f"{x_sorted=}")
# first way to recover the original array
i_rev = np.zeros(10, dtype=int)
i_rev[sorted_indices] = np.arange(10)
np.allclose(x, x_sorted[i_rev])
# second way to recover the original array
np.allclose(x, x_sorted[np.argsort(sorted_indices)])Fine-Tuning
With the selected completions, you then perform standard instruction fine-tuning on the current version of the model. More details can be found in the chapter on instruction tuning.
Implementation Details
The core hyperparameters for performing this training are very intuitive:
- Sampling parameters: Rejection sampling is directly dependent on the completions received from the model. Common settings for rejection sampling include temperatures above zero, e.g. between 0.7 and 1.0, with other modifications to parameters such as top-p or top-k sampling.
- Completions per prompt: Successful implementations of rejection sampling have included 10 to 30 or more completions for each prompt. Using too few completions will make training biased and/or noisy.
- Instruction tuning details: No clear training details for the instruction tuning during rejection sampling have been released. It is likely that they use slightly different settings than the initial instruction tuning phase of the model.
- Heterogeneous model generations: Some implementations of rejection sampling include generations from multiple models rather than just the current model that is going to be trained. Best practices on how to do this are not established.
- Reward model training: The reward model used will heavily impact the final result. For more resources on reward model training, see the relevant chapter.
When doing batch reward model inference, you can sort the tokenized completions by length so that the batches are of similar lengths. This eliminates the need to run inference on as many padding tokens and will improve throughput in exchange for minor implementation complexity.
Related: Best-of-N Sampling
Best-of-N (BoN) is a close relative of rejection sampling, where the same generate-and-score procedure is followed, but you do not fine-tune the model on the selected completions. Instead, BoN computes the best possible completion to a static prompt (or set of prompts) at inference time, and related techniques are often used in “Pro” tiers of chat models that spend extra compute to get an answer to your query.
Best-of-N sampling is often included as a baseline relative to RLHF training methods. It is important to remember that BoN does not modify the underlying model, but is a sampling technique. For this reason, comparisons of BoN sampling to online training methods, such as PPO, are still valid in some contexts. For example, you can still measure the KL distance when running BoN sampling relative to any other policy.
Here, we will show that when using simple BoN sampling over one prompt, both selection criteria shown above are equivalent.
Let \(R\) be a reward vector for our single prompt with \(N\) completions:
\[R = [r_1, r_2, ..., r_N]\qquad{(16)}\]
where \(r_j\) represents the reward for the j-th completion.
Using the argmax method, we select the best completion for the prompt:
\[S(R) = \arg\max_{j \in [1,N]} r_j\qquad{(17)}\]
Using the top-K method with \(K=1\) reduces to the same method, which is common practice.
Suggested Experiments
The companion implementation in code/rejection_sampling/ runs a complete GSM8K rejection-sampling pipeline: generate rollouts, score them with a reward model, select a training subset, fine-tune, and evaluate exact-match accuracy. The four configs are arranged as matched treatment/control pairs, so readers can ask whether the reward model is actually helping.
Build the rollout cache once.
cd code/ uv run python -m rejection_sampling.preprocess \ --config rejection_sampling/configs/top_per_prompt.yamlThis generates and scores completions for the shared GSM8K slice. Subsequent training configs reuse the cache as long as the generation and scoring settings stay unchanged.
Compare reward selection against random controls.
cd code/ uv run python -m rejection_sampling.train \ --config rejection_sampling/configs/top_per_prompt.yaml uv run python -m rejection_sampling.train \ --config rejection_sampling/configs/random_per_prompt.yaml uv run python -m rejection_sampling.train \ --config rejection_sampling/configs/top_k_overall.yaml uv run python -m rejection_sampling.train \ --config rejection_sampling/configs/random_k_overall.yamlRead results in matched pairs:
top_per_promptversusrandom_per_prompt, andtop_k_overallversusrandom_k_overall. If the reward-selected run does not beat its random baseline, the reward model or sampled completions are not giving useful signal on that slice.Vary how much choice the reward model gets. Copy one config and change
num_completions_per_prompt,temperature,top_p, andselection.top_k. More completions can improve the best available sample, but only if the reward model can separate good and bad answers.Try a smaller policy model. Set
model_nameto a smaller compatible instruct model, reducemax_train_samples, and rerun the same matched pairs. This makes the experiment cheaper and highlights whether rejection sampling is rescuing weak generations or merely selecting among already-good ones.