Direct-Alignment Algorithms
Direct Alignment Algorithms (DAAs) allow one to update models to solve the same RLHF objective without ever training an intermediate reward model or using reinforcement learning optimizers. DAAs solve the same preference learning problem we’ve been studying (with literally the same data!), in order to make language models more aligned, smarter, and easier to use. The lack of a reward model and online optimization makes DAAs far simpler to implement, reducing compute spent during training and making experimentation easier. This chapter details the complex mathematics done to derive these algorithms, and then shows that the sometimes tedious derivations result in simple implementations.
The most prominent DAA and one that catalyzed an entire academic movement of aligning language models is Direct Preference Optimization (DPO) [1]. At its core, DPO uses gradient ascent to solve the same constrained RLHF objective (see Chapter 3):
\[ \max_{\pi} \mathbb{E}_{x \sim \mathcal{D}}\mathbb{E}_{y \sim \pi(y|x)} \left[r_\theta(x, y)\right] - \beta \mathcal{D}_{\text{KL}}\left(\pi(y|x) \| \pi_{\text{ref}}(y|x)\right)\qquad{(1)}\]
Since its release in May of 2023, after a brief delay where the community figured out the right data and hyperparameters to use DPO with (specifically, surprisingly low learning rates), many popular models have used DPO or its variants, from Zephyr-\(\beta\) kickstarting it in October of 2023 [2], Llama 3 Instruct [3], Tülu 2 [4] and 3 [5], Nemotron 4 340B [6], and others. Technically, Sequence Likelihood Calibration (SLiC-HF) was the first modern direct alignment algorithm released [7], but it did not catch on due to a combination of factors (unwinding the adoption of research methods is always a tricky task).
The most impactful part of DPO and DAAs is lowering the barrier to entry to experimenting with language model post-training – it uses less compute, is easier to implement from scratch, and is easier to get working on both toy and production examples.
Throughout this chapter, we use \(x\) to denote prompts and \(y\) to denote completions. This notation is common in the language model literature, where methods operate on full prompt-completion pairs rather than individual tokens.
Direct Preference Optimization
Here we explain intuitions for how DPO works and re-derive the core equations fully.
How DPO Works
DPO at a surface level is directly optimizing a policy to solve the RLHF objective. The loss function for this, which we will revisit below in the derivations, compares how much the learned policy’s probability of chosen and rejected completions has shifted relative to a reference model. The loss function derived from a Bradley-Terry reward model follows:
\[ \mathcal{L}_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) = -\mathbb{E}_{(x, y_c, y_r) \sim \mathcal{D}}\left[ \log \sigma\left( \beta \log \frac{\pi_{\theta}(y_c \mid x)}{\pi_{\text{ref}}(y_c \mid x)} - \beta \log \frac{\pi_{\theta}(y_r \mid x)}{\pi_{\text{ref}}(y_r \mid x)} \right) \right] \qquad{(2)}\]
Inside the sigmoid, the first term \(\beta \log \frac{\pi_{\theta}(y_c | x)}{\pi_{\text{ref}}(y_c | x)}\) measures how much the policy has increased the probability of the chosen completion relative to the reference model, and the second term does the same for the rejected completion. The loss decreases when the chosen shift exceeds the rejected shift – i.e. when the policy learns to prefer the right response.
Throughout, \(\beta\) is a hyperparameter balancing the reward optimization to the KL divergence between the final model and the initial reference (i.e. balancing over-optimization, a crucial hyperparameter when using DPO correctly). This relies on the implicit reward for DPO training that replaces using an external reward model, which is a log-ratio of probabilities:
\[r(x, y) = \beta \log \frac{\pi_r(y \mid x)}{\pi_{\text{ref}}(y \mid x)}\qquad{(3)}\]
where \(\pi_r(y \mid x)\) is the exact, optimal reward policy that we are solving for. This comes from deriving the Bradley-Terry reward with respect to an optimal policy (shown in eq. 18), as shown in the Bradley-Terry model section of Chapter 5. Essentially, as stated in the DPO paper, this reparameterization gives us “the probability of human preference data in terms of the optimal policy rather than the reward model” – meaning we can bypass learning an explicit reward model entirely.
Let us consider the loss shown in eq. 2 that the optimizer must decrease. Here, the loss will be lower when the log-ratio of the chosen response is bigger than the log-ratio of the rejected response (normalized by the reference model). In practice, this is a sum of log-probabilities of the model across the sequence of tokens in the data presented. Hence, DPO is increasing the gap in relative log-probabilities between the chosen and rejected responses.
With the reward in eq. 3, we can write the gradient of the loss to further interpret what is going on:
\[\nabla_{\theta}\mathcal{L}_{\text{DPO}}(\pi_{\theta}; \pi_{\text{ref}}) = -\beta \mathbb{E}_{(x, y_c, y_r)\sim \mathcal{D}}\left[ w \cdot \left(\nabla_{\theta}\log \pi_{\theta}(y_c \mid x) - \nabla_{\theta}\log \pi_{\theta}(y_r \mid x)\right) \right]\qquad{(4)}\]
where \(w = \sigma\!\left(r_{\theta}(x, y_r) - r_{\theta}(x, y_c)\right)\).
Here, the gradient solves the above objective by doing the following:
- The first term within the sigmoid function, \(\sigma(\cdot)\), creates a weight of the parameter update from 0 to 1 that is higher when the reward estimate is incorrect. When the rejected sample is preferred over the chosen, the weight update should be larger!
- Second, the terms in the inner brackets \([\cdot]\) increase the likelihood of the chosen response \(y_c\) and decrease the likelihood of the rejected \(y_r\).
- These terms are weighted by \(\beta\), which controls how the update balances ordering the completions correctly relative to the KL divergence.
The core intuition is that DPO is fitting an implicit reward model whose corresponding optimal policy can be extracted in closed form (eq. 18, thanks to gradient descent and our ML tools). Because the DPO loss is directly differentiable, it is straightforward to compute the exact gradient, rather than needing to estimate it by training a reward model and sampling completions to score. What is often misunderstood is that DPO is learning a reward model at its core, hence the subtitle of the paper Your Language Model is Secretly a Reward Model. It is easy to confuse this with the DPO objective training a policy directly, hence studying the derivations below is good for a complete understanding.
With the implicit reward model learning, DPO is generating an optimal solution to the RLHF objective given the data in the dataset and the specific KL constraint in the objective \(\beta\). Here, DPO solves for the exact policy given a specific KL divergence because the generations are not online as in policy gradient algorithms – a core difference from the RL methods for preference tuning. In many ways, this makes the \(\beta\) value easier to tune with DPO relative to online RL methods, but crucially and intuitively the optimal value depends on the model being trained and the data training it.
At each batch of preference data, composed of many pairs of completions \(y_{chosen} \succ y_{rejected}\), DPO takes gradient steps directly towards the optimal solution. It is far simpler than policy gradient methods.
DPO Derivation
The DPO derivation takes two primary parts. First, the authors show the form of the policy that optimally solved the RLHF objective used throughout this book. Next, they show how to arrive at that solution from pairwise preference data (i.e. a Bradley-Terry model).
Deriving the Optimal RLHF Solution
To start, we should consider the RLHF optimization objective once again, here indicating we wish to maximize this quantity:
\[ \max_{\pi} \mathbb{E}_{x \sim \mathcal{D}}\mathbb{E}_{y \sim \pi(y|x)} \left[r_\theta(x, y)\right] - \beta \mathcal{D}_{\text{KL}}\left(\pi(y|x) \| \pi_{\text{ref}}(y|x)\right)\qquad{(5)}\]
Here, the dual expectation only applies to the sampling to compute the expected reward, as the KL term is still an analytical expression. First, let us expand the definition of KL-divergence. Recall that \(\mathcal{D}_{\text{KL}}(\pi \| \pi_{\text{ref}}) = \mathbb{E}_{y \sim \pi}\left[\log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)}\right]\), where the \(\pi(y|x)\) weighting in the sum becomes the sampling distribution. Since both terms now share the same expectation over \(y \sim \pi(y|x)\), we can combine them:
\[\max_{\pi} \mathbb{E}_{x \sim \mathcal{D}}\mathbb{E}_{y \sim \pi(y|x)}\left[r(x,y)-\beta\log\frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)}\right] \qquad{(6)}\]
Next, bring the negative sign out of the difference in brackets. To do this, split it into two terms:
\[ = \max_{\pi}\left(\mathbb{E}_{x \sim \mathcal{D}}\mathbb{E}_{y \sim \pi(y|x)}\left[r(x,y)\right] - \beta\,\mathbb{E}_{x \sim \mathcal{D}}\mathbb{E}_{y \sim \pi(y|x)}\left[\log\frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)}\right]\right) \qquad{(7)}\]
Then, multiply by \(-1\) to convert the maximization into a minimization:
\[ = \min_{\pi}\left(-\mathbb{E}_{x \sim \mathcal{D}}\mathbb{E}_{y \sim \pi(y|x)}\left[r(x,y)\right] + \beta\,\mathbb{E}_{x \sim \mathcal{D}}\mathbb{E}_{y \sim \pi(y|x)}\left[\log\frac{\pi(y|x)}{\pi_{\mathrm{ref}}(y|x)}\right]\right) \qquad{(8)}\]
Divide by \(\beta\) and recombine:
\[ = \min_{\pi}\left(\mathbb{E}_{x \sim \mathcal{D}}\mathbb{E}_{y \sim \pi(y|x)}\left[ \log\frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)} - \frac{1}{\beta}r(x,y) \right]\right) \qquad{(9)}\]
Next, we must introduce a partition function, \(Z(x)\):
\[ Z(x) = \sum_y \pi_{\text{ref}}(y|x)\exp\left(\frac{1}{\beta}r(x,y)\right) \qquad{(10)}\]
The partition function acts as a normalization factor for the unnormalized density \(\pi_{\text{ref}}(y|x)\exp\left(\frac{1}{\beta}r(x,y)\right)\), thereby making it a valid probability function over \(y\) for each fixed \(x\). The exact need for this will become clear shortly as we proceed with the derivation.
With this substituted in, we obtain our intermediate transformation:
\[ \min_{\pi}\mathbb{E}_{x\sim\mathcal{D}}\mathbb{E}_{y\sim\pi(y|x)}\left[\log\frac{\pi(y|x)}{\frac{1}{Z(x)}\pi_{\text{ref}}(y|x)\exp\left(\frac{1}{\beta}r(x,y)\right)} - \log Z(x)\right] \qquad{(11)}\]
To see how this is obtained, consider the internal part of the optimization in brackets of eq. 9:
\[ \log\frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)} - \frac{1}{\beta}r(x,y) \qquad{(12)}\]
Then, add \(\log Z(x) - \log Z(x)\) to both sides:
\[ = \log\frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)} - \frac{1}{\beta}r(x,y) + \log Z(x) - \log Z(x) \qquad{(13)}\]
Then, we group the terms:
\[ = \left( \log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)} + \log Z(x) \right) - \log Z(x) - \frac{1}{\beta}r(x,y) \qquad{(14)}\]
With \(\log(x) + \log(y) = \log(x\cdot y)\) (and moving \(Z\) to the denominator), we get:
\[ = \log \frac{\pi(y|x)}{\frac{1}{Z(x)}\pi_{\text{ref}}(y|x)}- \log Z(x) - \frac{1}{\beta}r(x,y) \qquad{(15)}\]
Next, we expand \(\frac{1}{\beta}r(x,y)\) to \(\log \exp \frac{1}{\beta}r(x,y)\) and do the same operation to get eq. 11, which we slightly rewrite here:
\[ \min_{\pi}\mathbb{E}_{x\sim\mathcal{D}} \left[ \mathbb{E}_{y\sim\pi(y|x)}\left[\log\frac{\pi(y|x)}{\frac{1}{Z(x)}\pi_{\text{ref}}(y|x)\exp\left(\frac{1}{\beta}r(x,y)\right)} \right] - \log Z(x)\right] \qquad{(16)}\]
With this optimization form, we need to actually solve for the optimal policy \(\pi^*\). Since we introduced the partition function \(Z(x)\), thereby making the term \(\frac{1}{Z(x)}\pi_{\text{ref}}(y|x)\exp\left(\frac{1}{\beta}r(x,y)\right)\) a valid probability distribution over \(y\), we can recognize that the inner expectation is in fact a proper KL-divergence!
\[ \min_{\pi}\mathbb{E}_{x\sim\mathcal{D}}\left[\mathcal{D}_{\text{KL}} \left(\pi(y|x) \middle\| \frac{1}{Z(x)}\pi_{\text{ref}}(y|x)\exp\left(\frac{1}{\beta}r(x,y)\right) \right) - \log Z(x)\right] \qquad{(17)}\]
Since the term \(\log Z(x)\) does not depend on \(\pi\) (the policy we are optimizing), we can ignore it. This leaves us with just the KL divergence between the policy we are learning and a form relating the partition, \(\beta\), reward, and reference policy. Gibbs’ inequality tells us this is minimized at a distance of 0, only when the two quantities are equal! Hence, we get an optimal policy:
\[ \pi^*(y|x) = \pi(y|x) = \frac{1}{Z(x)}\pi_{\text{ref}}(y|x)\exp\left(\frac{1}{\beta}r(x,y)\right) \qquad{(18)}\]
Deriving DPO Objectives for BT Models
To start, recall from Chapter 5 on Reward Modeling and Chapter 11 on Preference Data that a Bradley-Terry model of human preferences is formed as:
\[p^*(y_1 \succ y_2 \mid x) = \frac{\exp\left(r^*(x,y_1)\right)}{\exp\left(r^*(x,y_1)\right) + \exp\left(r^*(x, y_2)\right)} \qquad{(19)}\]
By manipulating eq. 18, we can solve for the optimal reward. First, take the logarithm of both sides:
\[\log \pi^*(y|x) = \log \left( \frac{1}{Z(x)}\pi_{\text{ref}}(y|x)\exp\left(\frac{1}{\beta}r^*(x,y)\right) \right)\qquad{(20)}\]
Expanding the right-hand side using \(\log(abc) = \log a + \log b + \log c\):
\[\log \pi^*(y|x) = -\log Z(x) + \log \pi_{\text{ref}}(y|x) + \frac{1}{\beta}r^*(x,y)\qquad{(21)}\]
Rearranging to solve for \(r^*(x,y)\):
\[\frac{1}{\beta}r^*(x,y) = \log \pi^*(y|x) - \log \pi_{\text{ref}}(y|x) + \log Z(x)\qquad{(22)}\]
Multiplying both sides by \(\beta\):
\[r^*(x, y) = \beta \log \frac{\pi^*(y \mid x)}{\pi_{\text{ref}}(y \mid x)} + \beta \log Z(x)\qquad{(23)}\]
We then can substitute the reward into the Bradley-Terry equation shown in eq. 19 to obtain:
\[p^*(y_1 \succ y_2 \mid x) = \frac{\exp\left(\beta \log \frac{\pi^*(y_1 \mid x)}{\pi_{\text{ref}}(y_1 \mid x)} + \beta \log Z(x)\right)} {\exp\left(\beta \log \frac{\pi^*(y_1 \mid x)}{\pi_{\text{ref}}(y_1 \mid x)} + \beta \log Z(x)\right) + \exp\left(\beta \log \frac{\pi^*(y_2 \mid x)}{\pi_{\text{ref}}(y_2 \mid x)} + \beta \log Z(x)\right)} \qquad{(24)}\]
By decomposing the exponential expressions from \(e^{a+b}\) to \(e^a e^b\) and then cancelling out the terms \(e^{\beta \log Z(x)}\), this simplifies to:
\[p^*(y_1 \succ y_2 \mid x) = \frac{\exp\left(\beta \log \frac{\pi^*(y_1 \mid x)}{\pi_{\text{ref}}(y_1 \mid x)}\right)} {\exp\left(\beta \log \frac{\pi^*(y_1 \mid x)}{\pi_{\text{ref}}(y_1 \mid x)}\right) + \exp\left(\beta \log \frac{\pi^*(y_2 \mid x)}{\pi_{\text{ref}}(y_2 \mid x)}\right)} \qquad{(25)}\]
Then, multiply the numerator and denominator by \(\exp\left(-\beta \log \frac{\pi^*(y_1 \mid x)}{\pi_{\text{ref}}(y_1 \mid x)}\right)\) to obtain:
\[p^*(y_1 \succ y_2 \mid x) = \frac{1}{1 + \exp\left(\beta \log \frac{\pi^*(y_2 \mid x)}{\pi_{\text{ref}}(y_2 \mid x)} - \beta \log \frac{\pi^*(y_1 \mid x)}{\pi_{\text{ref}}(y_1 \mid x)}\right)} \qquad{(26)}\]
Finally, with the definition of a sigmoid function as \(\sigma(x) = \frac{1}{1+e^{-x}}\), we obtain:
\[p^*(y_1 \succ y_2 \mid x) = \sigma\left(\beta \log \frac{\pi^*(y_1 \mid x)}{\pi_{\text{ref}}(y_1 \mid x)} - \beta \log \frac{\pi^*(y_2 \mid x)}{\pi_{\text{ref}}(y_2 \mid x)}\right) \qquad{(27)}\]
This is the likelihood of preference data under the Bradley-Terry model, given the optimal policy \(\pi^*\). Recall from Chapter 5 on Reward Modeling that we derived the Bradley-Terry objective as maximizing the likelihood, or equivalently minimizing the negative log-likelihood, which gives us the loss: \[ \begin{aligned} \mathcal{L}_{\text{DPO}}(\pi_{\theta}; \pi_{\text{ref}}) &= -\mathbb{E}_{(x,y_c,y_r)\sim\mathcal{D}}\left[ \log p(y_c \succ y_r \mid x) \right] \\ &= -\mathbb{E}_{(x,y_c,y_r)\sim\mathcal{D}}\left[ \log \sigma\left(\beta \log \frac{\pi_{\theta}(y_c|x)}{\pi_{\text{ref}}(y_c|x)} - \beta \log \frac{\pi_{\theta}(y_r|x)}{\pi_{\text{ref}}(y_r|x)}\right)\right] \end{aligned} \qquad{(28)}\]
This is the loss function for DPO, in the form shown in eq. 2. The DPO paper has an additional derivation for the objective under a Plackett-Luce Model, which is far less used in practice [1].
Deriving the BT DPO Gradient
We used the DPO gradient shown in eq. 4 to explain intuitions for how the model learns. To derive this, we must take the gradient of eq. 28 with respect to the model parameters.
\[\nabla_{\theta}\mathcal{L}_{\text{DPO}}(\pi_{\theta}; \pi_{\text{ref}}) = -\nabla_{\theta}\mathbb{E}_{(x,y_c,y_r)\sim\mathcal{D}}\left[ \log \sigma\left(\beta \log \frac{\pi_{\theta}(y_c|x)}{\pi_{\text{ref}}(y_c|x)} - \beta \log \frac{\pi_{\theta}(y_r|x)}{\pi_{\text{ref}}(y_r|x)}\right)\right] \qquad{(29)}\]
To start, this can be rewritten. We know that the derivative of a sigmoid function \(\frac{d}{dx} \sigma(x) = \sigma(x)(1-\sigma(x))\), the derivative of the logarithm \(\frac{d}{dx} \log x = \frac{1}{x}\), and properties of sigmoid \(\sigma(-x)=1-\sigma(x)\), so we can reformat the above equation.
First, let \(u=\beta \log \frac{\pi_{\theta}(y_c|x)}{\pi_{\text{ref}}(y_c|x)} - \beta \log \frac{\pi_{\theta}(y_r|x)}{\pi_{\text{ref}}(y_r|x)}\) (the expression inside the sigmoid). Then, we have
\[\nabla_{\theta}\mathcal{L}_{\text{DPO}}(\pi_{\theta};\pi_{\text{ref}}) = -\mathbb{E}_{(x, y_c, y_r)\sim \mathcal{D}}\left[\frac{\sigma'(u)}{\sigma(u)}\nabla_{\theta}u\right] \qquad{(30)}\]
Expanding this and using the above expressions for sigmoid and logarithms results in the gradient introduced earlier:
\[ -\mathbb{E}_{(x,y_c,y_r)\sim\mathcal{D}}\left[\beta\sigma\left(\beta\log\frac{\pi_{\theta}(y_r|x)}{\pi_{\text{ref}}(y_r|x)} - \beta\log\frac{\pi_{\theta}(y_c|x)}{\pi_{\text{ref}}(y_c|x)}\right)\left[\nabla_{\theta}\log\pi_{\theta}(y_c|x)-\nabla_{\theta}\log\pi_{\theta}(y_r|x)\right]\right] \qquad{(31)}\]
Numerical Concerns, Weaknesses, and Alternatives
Many variants of the DPO algorithm have been proposed to address weaknesses of DPO. For example, without rollouts where a reward model can rate generations, DPO treats every pair of preference data with equal weight. In reality, as seen in Chapter 11 on Preference Data, there are many ways of capturing preference data with a richer label than binary. Multiple algorithms have been proposed to re-balance the optimization away from treating each pair equally.
- REgression to RElative REward Based RL (REBEL) adds signal from a reward model, as a margin between chosen and rejected responses, rather than solely the pairwise preference data, to more accurately solve the RLHF problem [8].
- Conservative DPO (cDPO) and Identity Preference Optimization (IPO) address overfitting by assuming noise in the preference data. cDPO assumes N percent of the data is incorrectly labeled [1] and IPO changes the optimization to soften the probability of preference rather than optimize directly from a label [9]. Practically, IPO changes the preference probability to a nonlinear function, moving away from the Bradley-Terry assumption, with \(\Psi(q) = \log\left(\frac{q}{1-q}\right)\).
- DPO with an offset (ODPO) “requires the difference between the likelihood of the preferred and dispreferred response to be greater than an offset value” [10] – do not treat every data pair equally, but this can come at the cost of a more difficult labeling environment.
Some variants of DPO attempt to either improve the learning signal by making small changes to the loss or make the application more efficient by reducing memory usage.
- Odds Ratio Policy Optimization (ORPO) directly updates the policy model with a pull towards the chosen response, similar to the instruction fine-tuning loss, with a small penalty on the chosen response [11]. This change of loss function removes the need for a reference model, simplifying the setup. The best way to view ORPO is as DPO inspired, rather than a DPO derivative.
- Simple Preference Optimization (SimPO) makes a minor change to the DPO optimization, by averaging the log-probabilities rather than summing them or adding length normalization, to improve performance [12].
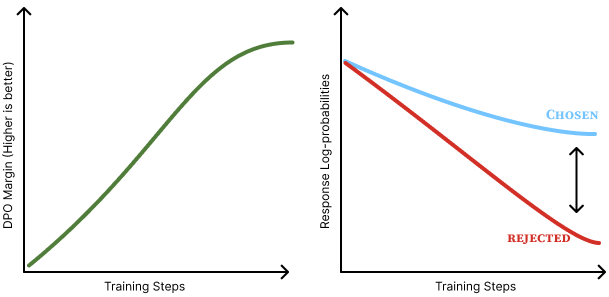
One of the core issues apparent in DPO is that the optimization drives only to increase the margin between the probability of the chosen and rejected responses. Numerically, the model reduces the probability of both the chosen and rejected responses, but the rejected response is reduced by a greater extent as shown in fig. 2. Intuitively, it is not clear how this generalizes, but work has posited that it increases the probability of unaddressed behaviors – i.e. tokens that the language model could generate, but are not in the distribution of the post-training datasets [13] [14]. Simple methods—such as Cal-DPO [15], which adjusts the optimization process, and AlphaPO [16], which modifies the reward shape—mitigate this preference displacement. In practice, the exact impact of this is not well known, but points to a potential reason why online methods can outperform vanilla DPO.
The other primary reason posited for DPO-like methods to have a lower ceiling on performance than online (RL based) RLHF methods is that the training signal comes from completions from previous or other models. Online variants of DPO alleviate these limitations by generating new completions and incorporating a preference signal at training time. Online DPO [17] samples generations from the current model, while Discriminator-Guided DPO (D2PO) [18] uses reward model relabelling to create new preference data on the fly, and many more variants exist.
There is a long list of other DAA variants, such as Direct Nash Optimization (DNO) [19] or Binary Classifier Optimization (BCO) [20], but the choice of algorithm is far less important than the initial model and the data used [5] [21] [22].
Implementation Details
DAAs such as DPO are implemented very differently than policy gradient optimizers. The DPO loss, taken from the original implementation, largely can be summarized as follows [1]:
# Log-probability gaps for the policy and the frozen reference model
pi_logratios = policy_chosen_logps - policy_rejected_logps
ref_logratios = reference_chosen_logps - reference_rejected_logps
# Difference of log-ratios: positive when the policy
# shifts probability toward the chosen completion
logits = pi_logratios - ref_logratios
# DPO loss: negative log-sigmoid drives the policy to
# widen the gap between chosen and rejected
losses = -F.logsigmoid(beta * logits)
# Implicit rewards (detached -- used for logging only)
chosen_rewards = beta * (policy_chosen_logps - reference_chosen_logps).detach()
rejected_rewards = beta * (policy_rejected_logps - reference_rejected_logps).detach()This can be used in standard language model training stacks as this information is already collated during the forward pass of a model (with the addition of a reference model).
In most ways, DAAs are simpler and a quality of life improvement, but they also offer a different set of considerations.
- KL divergence is static: In DPO and other algorithms, the KL divergence is set explicitly by the \(\beta\) parameter that balances the distance penalty to the optimization. This is due to the fact that DPO takes gradient steps towards the optimal solution to the RLHF objective given the data – it steps exactly to the solution set by the \(\beta\) term. On the other hand, RL based optimizers take steps based on the batch and recent data.
- Caching log-probabilities: Simple implementations of DPO do the forward passes for the policy model and reference models at the same time for convenience with respect to the loss function. However, this doubles the memory used and results in increased GPU usage. To avoid this, one can compute the log-probabilities of the reference model over the training dataset first, then reuse those cached reference log-probabilities when computing the loss and updating the parameters per batch, reducing the peak memory usage by 50%.
DAAs with Synthetic Preference Data
Most of the popular datasets for performing preference fine-tuning with DAAs these days are synthetic preferences where a frontier model rates outputs from other models as the winner or the loser. Prominent examples include UltraFeedback (the first of this category) [23], Tülu 3 (built with an expanded UltraFeedback methodology) [5], SmolLM 3’s data [24], or the Dolci Pref dataset released with Olmo 3 [25].
The best practices for constructing these datasets are still evolving. Tülu 3 and datasets around its release in November of 2024 demonstrated that synthetic, pairwise preference data needs to be “on-policy” in a sense that some completions are generated from the model you’re fine-tuning (while being mixed in a bigger model pool). This on-policy nature of the data ensured that the DAA would optimize the correct token space within which the model generates – as the loss functions are contrastive and less direct than instruction fine-tuning. Later, with the release of Olmo 3 and SmolLM 3 in 2025, other works supported a different theory called Delta Learning, which argues that the difference between the chosen and rejected completions is more important to learning than exactly which models are used for the completions [26]. For example, in both of these two referenced models, the chosen responses are from Qwen 3 32B and the rejected responses are from Qwen 3 0.6B – both authors developed this pairing concurrently and independently.
Overall, training models on synthetic preference data with DAAs is the place most practitioners should start, given the simplicity of implementation and strong performance relative to preference fine-tuning with reinforcement learning based methods. Other minor issues exist when using extensive, synthetic preference data, such as biases of the model judging between completions. Given that frontier models such as GPT-4 are known to have length bias [27] and a preference for outputs that match themselves [28] (see Chapter 12 for more information), it is slightly more likely for a piece of text in the “chosen” section of the dataset to be either from an OpenAI model or another strong model that is stylistically similar to it.
To conclude this section, we’ll cover an intuition for how these methods change the generations of the model being trained. At a high level, most DAAs optimize to increase the margin between the probability of “chosen” and “rejected” completions (some less popular algorithms are designed to slightly change these dynamics, but the core remains). As discussed earlier in this chapter (see fig. 2), this often means both probabilities decrease, but the rejected response decreases by a greater extent. Each token in a sequence receives a different gradient (magnitude and direction) based on how much it contributed to the overall preference margin, allowing the optimizer to identify which tokens matter most to the outcome.
DAAs vs. RL: Online vs. Offline Data
Broadly, the argument boils down to one question: Do we need the inner workings of reinforcement learning, with value functions, policy gradients, and all, to align language models with RLHF? This, like most questions phrased this way, is overly simple. Of course, both methods are well-established, but it is important to illustrate where the fundamental differences and performance manifolds lie.
Multiple reports have concluded that policy-gradient based and RL methods outperform DPO and its variants. The arguments take different forms, from training models with different algorithms but controlled data [29] [30] or studying the role of on-policy data within the RL optimization loop [31]. In all of these cases, DPO algorithms are a hair behind.
Even with this performance delta, DAAs are still used extensively in leading models due to their simplicity. DAAs provide a controlled environment where iterations on training data and other configurations can be made rapidly, and given that data is often far more important than algorithms, using DPO can be fine.
With the emergence of reasoning models that are primarily trained with RL, further investment will return to using RL for preference-tuning, which in the long-term will improve the robustness of RL infrastructure and cement this margin between DAAs and RL for optimizing from human feedback.
Suggested Experiments
The companion code in code/direct_alignment/ trains DPO and several related losses on preference data. This is the most accessible place to start experimenting with preference tuning because the setup is offline: no reward model server or rollout loop is required.
Train a small DPO run on UltraFeedback.
cd code/ uv run python -m direct_alignment.train --loss dpo --max_samples 1000Watch
loss,accuracy,margins,chosen_rewards, andrejected_rewards. The main sanity check is that the implicit reward margin should move in the desired direction without the model’s sample generations collapsing.Compare DPO, IPO, and length-normalized DPO.
cd code/ uv run python -m direct_alignment.train --config direct_alignment/configs/dpo.yaml uv run python -m direct_alignment.train --config direct_alignment/configs/ipo.yaml uv run python -m direct_alignment.train --config direct_alignment/configs/dpo_norm.yamlCompare the margin scale and the learning rate sensitivity. IPO’s loss is not on the same numeric scale as DPO, so read it through
accuracyand margin behavior rather than raw loss alone.Try the reference-free variants carefully. Run SimPO or ORPO from their configs, then inspect the generated samples that are logged during training. These losses are more sensitive to log-probability scaling and learning rate, which makes them useful debugging exercises.
cd code/ uv run python -m direct_alignment.train --config direct_alignment/configs/simpo.yaml uv run python -m direct_alignment.train --config direct_alignment/configs/orpo.yamlChange the data before changing the loss. Keep the loss fixed and vary
--max_samples,--max_length, or the preference dataset. If the results move more than changing between DPO-like objectives, that is an empirical reminder of a central theme in preference tuning: data usually dominates small algorithmic differences.